

Want More? Follow Teng Yan and Chain of Thought on X
Subscribe for timely research and insights—delivered to your inbox.
TL;DR
Atoma is building the foundation for an AI-first blockchain, unlocking massive potential for decentralized, verifiable, and private AI.
By decoupling execution from blockchain state while maintaining accountability, Atoma ensures both performance and trust.
The network is built on two key components: (1) Compute layer, and (2) Verification + Privacy layer
Atoma employs advanced optimization techniques to run models efficiently on lower-spec hardware. This foundation delivers inference speeds that surpass traditional vLLM setups.
Trusted Execution Environments (TEEs) are used to provide truly confidential computing and verifiable outputs.
Its application layer enables developers to build privacy-preserving AI applications with minimal overhead, combining verifiability and security.
Now live on Sui’s Mainnet, Atoma can power fast and efficient AI applications with built-in privacy and decentralization.
Back in 2015, I was working in an AI startup.
We used traditional machine learning and natural language processing to pull insights from doctor’s notes (messy and unstructured). And built tools to accelerate clinical trials and drug development.
This was years before ChatGPT made generative AI a topic of dinner-table debate. There were no massive pre-trained models ready to plug into our workflows. Every capability we needed, we had to build from scratch. It was slow, painful, and messy.
But it also made it clear to me: AI is not just going to be big—it was going to reshape the way we work, live, and think.
Fast-forward to today, and my prediction feels almost…too modest.
Open-source models like DeepSeek R1 are nipping at the heels of the incumbents, while a flood of AI-powered applications continues to redefine what’s possible.
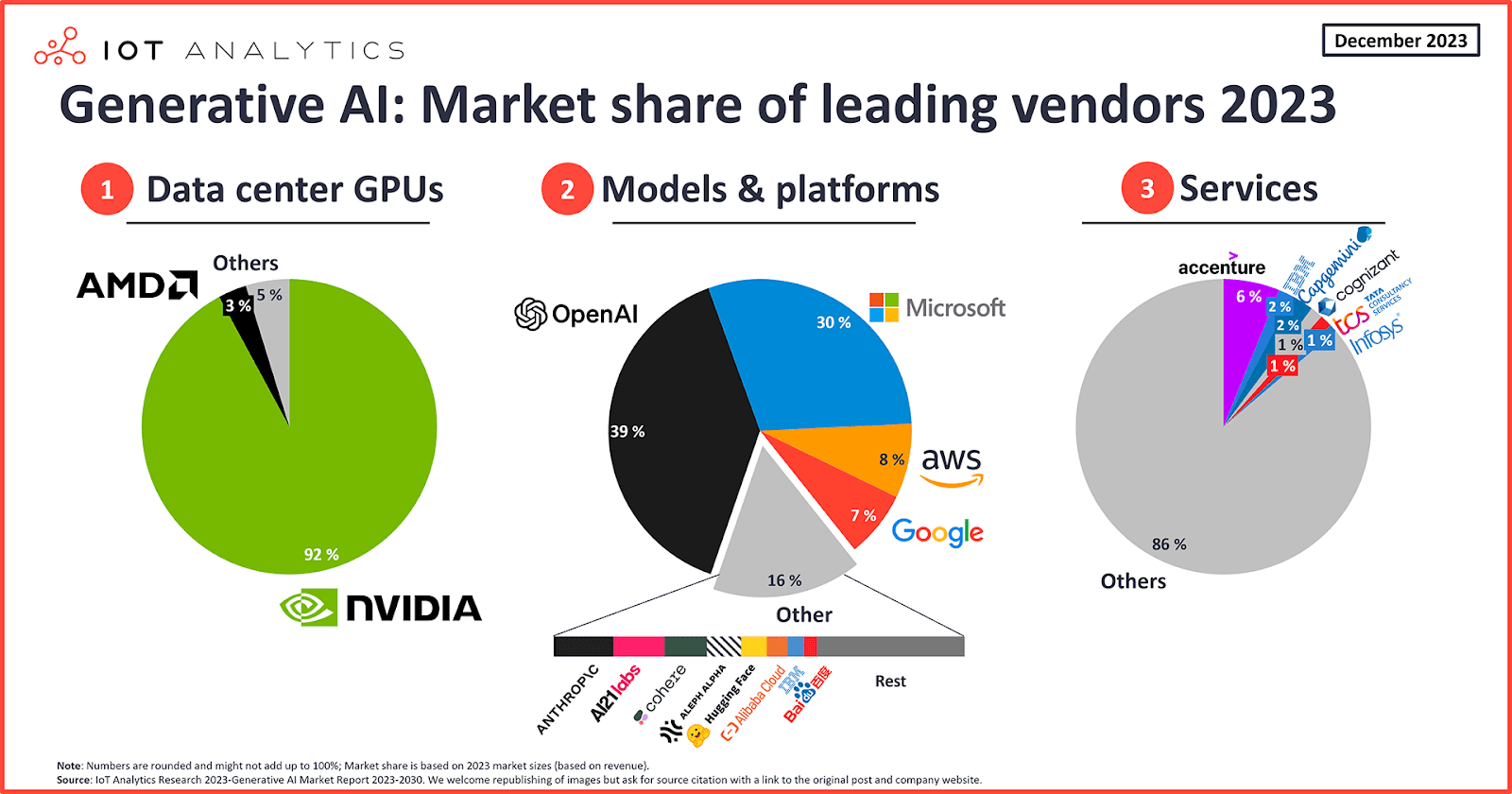
Yet we have a huge problem.
AI is consolidating at an alarming rate. Proprietary data centres, mostly controlled by Big Tech, dominate the field. And why wouldn’t they? It takes enormous amounts of specialised hardware (hello, GPUs) and sky-high budgets to power the AI we use daily. The cost of entry is so high that most startups and individuals can’t even make it to the starting line.
Atoma is rethinking how AI happens—how it’s delivered, consumed, and scaled. By leveraging privacy-preserving Trusted Execution Environments (TEEs) and creating an open GPU marketplace, Atoma is building a system where powerful AI models are accessible to anyone, anywhere. No gatekeepers. No blind trust required.
Our research piece takes a deep dive into Atoma and their unique approach to some of AI’s thorniest challenges: How do you guarantee trust in a trustless system? How do you safeguard user data privacy while maintaining performance?
I’ve been following Atoma’s journey since early 2024, watching their vision evolve as they quietly but relentlessly built toward it. They’re not chasing the hype or scrambling to launch the next shiny agent project.
Instead, they have focused on building foundational infrastructure for decentralised AI. It’s not sexy, but it's critical.
Why Verifiable AI Matters
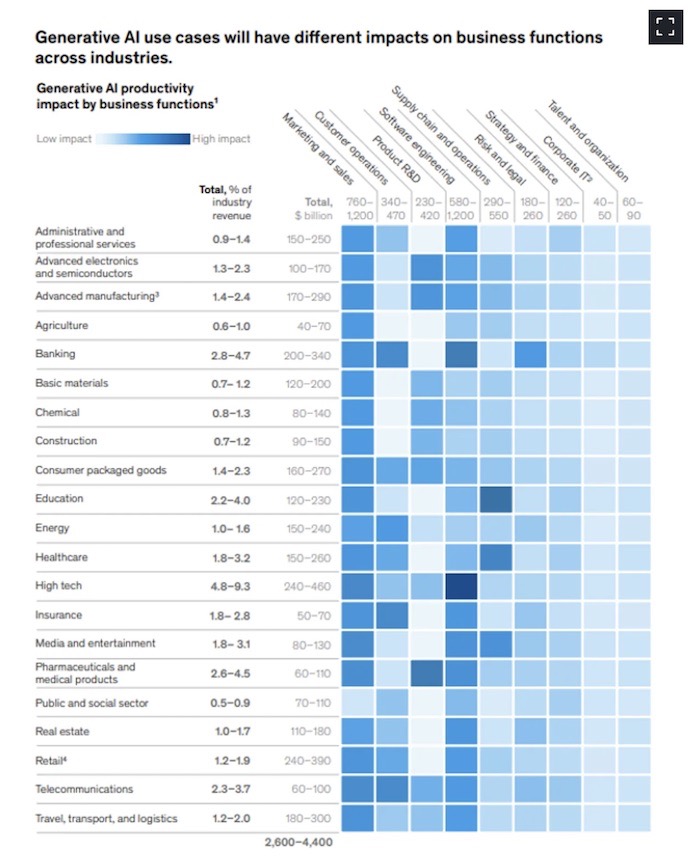
Source: McKinsey Generative AI report 2023
The $4 Trillion AI Wave
McKinsey estimates that generative AI could deliver a mind-boggling $2.6–4.4 trillion in annual economic benefits in the coming years.
This is bigger than the total GDP of major developed nations, implying that in the not-so-distant future, AI will be everywhere: scanning for diseases, creating personalised gym routines, auto-generating your marketing campaigns, powering entire robotic factories…
But if that future is fully centralised, imagine the insane power that 3–5 corporations hold. Regulators, smaller countries—everyone may become hostage to these giant providers. So, a push toward decentralised solutions is more than a “cool factor”—it’s existential for trust, competition, and innovation.
The Trust Deficit
Recent fiascos with AI “hallucinating” or giving extremely biased outputs highlight one basic fact: once AI is out of the lab and directly impacting real lives, trust is critical. If you’re building a financial app or a healthcare AI, an incorrect output can literally cause bankruptcies or harm patients.
Right now, there’s no easy way to confirm that an AI’s results are:
Accurately computed (i.e., you got the full-power model, not a cheap knockoff).
Not manipulated by hidden agendas.

Source: https://blogs.library.duke.edu/
Imagine you’re running a website that offers a personalised chatbot. Instead of relying on centralised providers like OpenAI, you tap into Atoma’s decentralised network. You request a popular model like “DeepSeek R1,” and the system routes your job to nodes advertising their ability to handle it. These nodes process your input and deliver the results back to you.
Sounds simple, right?
But what happens if a node sneaks in a smaller, less capable model instead? That’s where Atoma’s verification capabilities come in.
Privacy Pressures
The other big pain point: your data. In traditional AI setups, your data is decrypted in some random data centre, meaning the operator can theoretically access it. That’s not cool.
Atoma uses Trusted Execution Environments (TEEs) on GPUs to keep data and model computations in secure enclaves. No more eavesdropping from server staff or unknown actors. The data is encrypted at every stage, drastically reducing the chance of a catastrophic leak.
While centralised solutions like Microsoft Azure Confidential Computing also use TEEs to safeguard data in use, they come with an inherent limitation: single points of failure. A breach or compromise could expose enormous amounts of sensitive information.
Case-in-point: A major AWS outage in December 2021 disrupted services ranging from Netflix to Slack, illustrating the fragility of centralised infrastructures. These are not as uncommon as we think.
Accessibility is another bottleneck. Azure offers only a single instance of confidential compute nodes, with endpoints available in just four regions—a severe constraint for global users. And then there’s the cost. Azure’s confidential compute services are significantly more expensive than standard GPU providers.
In contrast, decentralised networks distribute data and computational tasks across multiple nodes, eliminating single points of failure and enhancing resilience against attacks. In such a setup, even if one node is compromised, the overall system remains secure and operational.
As AI becomes embedded in more facets of society, privacy and verifiability are no longer optional—they’re essential. AI systems must not only process data securely but also produce outputs that are provably trustworthy.
Without these safeguards, how can we trust the AI?
Atoma — Product Architecture
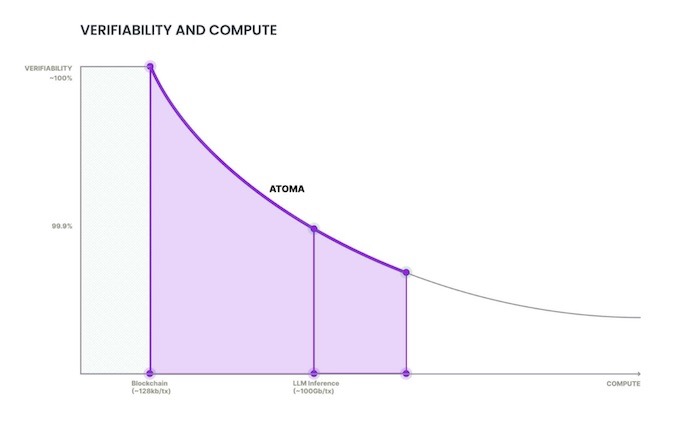
Atoma’s breakthrough lies in its ability to decouple execution from the blockchain state while still leveraging the blockchain for accountability.
Their approach recognises a fundamental bottleneck: while blockchains like Bitcoin have demonstrated their capacity to marshal vast compute resources (already 500 times more powerful than the world’s largest supercomputer), their bandwidth limitations and transaction costs make them impractical for real-time AI applications.
The Atoma team sees this as a critical problem to solve. Reducing the blockchain footprint while maintaining decentralisation is the key to unlocking scalable, real-time AI systems like autonomous, sovereign AI agents.
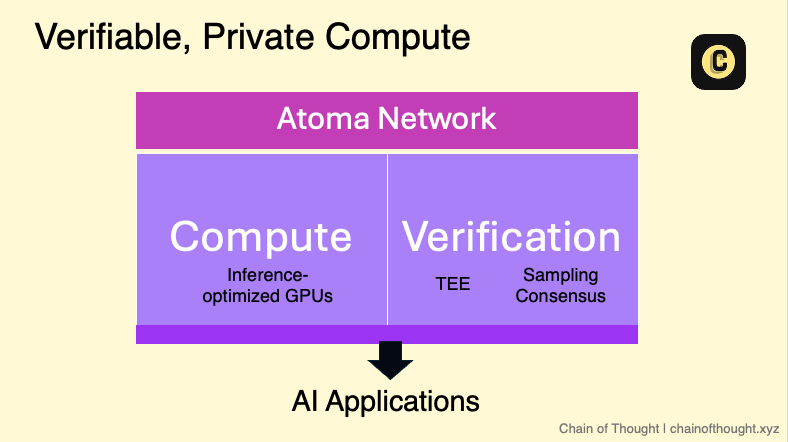
There are 2 key components to Atoma, each serving a distinct and complementary purpose.
Compute layer
Verification + Privacy layer
If you think of these layers as a stack—or, better yet, a perfectly constructed sandwich—they work together to deliver a unified and scalable system.
#1 — Compute layer
Atoma’s compute layer orchestrates a global network of node operators—think GPU owners and professional data centres—that specialises in AI computation.
These nodes, once underutilised and sitting idle in data centres or locked into proprietary systems, can now be part of an open, decentralised marketplace. Developers pay on a per-request basis, creating a free market for AI resources and eliminating the lock-in of traditional single-vendor setups.
Why is this special?
Permissionless: You don’t need to go through a KYC process to offer your GPU resources.
Scalable: The network automatically scales as more machines join the marketplace.
API-Compatible: Plug in via an OpenAI-like API; you can route your AI calls through Atoma and pick a node with the GPU type or price that suits you.
But I want to make the distinction clear: Atoma doesn’t just aggregate GPUs. It optimises them for the unique demands of AI workloads.
Unlike traditional GPU networks, Atoma is engineered for AI-specific tasks like inference, model refinement, and data embedding. The design of the network bridges the gap between high-performance data centre GPUs and consumer-grade hardware, including MacBook Pros.

Orchestrating distributed compute is way harder than solving a 11 x 11 x 11 Rubix cube.
This is a lot harder than it sounds. Running a distributed GPU network is like solving a Rubik’s Cube with moving parts. You’re dealing with a multi-layered puzzle that includes resource allocation, dynamic workload scaling, seamless load balancing across nodes and GPUs, latency management, efficient data transfer, fault tolerance, and the quirks of heterogeneous hardware scattered across the globe.
Many existing GPU providers stumble once the network grows beyond a certain size or cluster. Proper architecture design is essential for things to work properly. I wrote about this in our Crypto AI thesis on decentralised compute.
AI computation isn’t one-size-fits-all. Training models demands clusters of GPUs with massive memory and bandwidth to process data-intensive tasks. Inference, on the other hand, prioritises low latency and can run on less specialised hardware.
Atoma’s initial release focuses on inference while laying the groundwork for a future in which its infrastructure can also handle AI training on sensitive data.
Inference: Lean, Fast, and Scalable
Atoma uses advanced techniques to optimise inference, enabling models to run efficiently even on lower-spec hardware.
FlashAttention and PagedAttention streamline memory usage, reducing resource overhead without sacrificing performance. This makes high-performance inference accessible across a broader range of hardware configurations.
I’m probably not the best person to explain the finer technical details of this, but in my layman's understanding, FlashAttention minimises unnecessary transfers between high-bandwidth memory (HBM) and on-chip memory (SRAM) when using attention mechanisms in transformer models.
Think of it like making sandwiches in a kitchen: FlashAttention brings all the ingredients to the counter in one trip, assembles the sandwiches efficiently, and puts everything back in a single go.

PagedAttention, meanwhile, is a memory-efficient algorithm that works like organising books in a library.
Instead of cramming all the books onto one massive shelf in traditional transformer models, they’re distributed across smaller, scattered shelves (KV blocks). A catalogue (lookup table) helps locate books quickly, and you fetch only the shelves you need for your task, saving space and effort.
Atoma pushes efficiency further with Fully Sharded Data Parallelism (FSDP), a technique that distributes model parameters across multiple GPUs, enabling simultaneous computation. Each GPU stores only the required parameters, optimising resource usage and allowing nodes to process larger data batches and handle more concurrent requests.
Atoma’s software stack is built around Candle, a Rust-native AI framework designed for speed and hardware efficiency. Unlike bulkier frameworks like PyTorch, Candle operates closer to the hardware, enabling faster and more resource-efficient performance.
By combining these advanced techniques, Atoma ensures its infrastructure delivers unparalleled inference performance. FlashAttention and PagedAttention handle batching efficiently, while FSDP distributes model weights across GPUs co-located within nodes.
This foundation powers their new stack, dubbed “atoma-infer,” which promises inference speeds that outpace traditional vLLM setups.
Their high-speed inference supports even massive models like Llama-3.1-405B at full precision. In a batched request, their top nodes generate up to 2,200 tokens per second on a non-quantized Llama-3.1-405B-Instruct model, which requires ~1TB of VRAM.
This is orders of magnitude beyond human reading speed (10-20 tokens/sec).
Atoma’s nodes are built around open-source models, which the team believes will rival closed-source models. To streamline inference, nodes ensure model weights are available locally, eliminating delays from downloading weights when a request is received.
As Hisham (co-founder) puts it:
“People are starting to see the potential in open source. The dust has settled, and the builders are speaking—there’s five years of product development to be done even with current intelligence.”
Node Registry and Staking
Then there’s the trust issue.
Since Atoma’s network operates in a trustless environment where anyone can participate, it needs to be able to weed out bad actors. It does this using a reputation system and staking.
When mainnet is live, nodes will stake tokens as collateral, and those who underperform or act maliciously are penalised. High-reputation nodes get first dibs on the most lucrative tasks, aligning incentives to keep the network running smoothly.
Node operators who want to join Atoma stake tokens and register on the network. If they misbehave—provide false outputs, go offline for days, or run the wrong model—they can get slashed (lose part or all of their token collateral). This creates strong economic incentives: run your node honestly, or you lose money.
Why stake collateral? Because cheating can pay. For example, a node might run a smaller model to collect the same fees with a fraction of the GPU cost. But if they’re caught—thanks to random sampling or a user-initiated dispute—they lose their stake. Over time, no rational node wants to take that gamble.
AI Model Subscriptions
Atoma is model-agnostic. That means it can run everything from small stable diffusion image models, to 70B LLMs, to the latest 671B DeepSeek R1.
When a node wants to serve a specific model, it subscribes to that model in Atoma’s on-chain registry, claiming the GPU specs needed (e.g., “I run 4 × A100 GPUs, 80GB each”). The node also downloads the required model weights and checks its Merkle root hash to confirm it has the correct version.
Any developer requesting that model can see which nodes are subscribed, their cost, and their track record. They choose the node(s) they trust or are randomly assigned by Atoma’s logic, and the process begins.
Free-Market Economics
In practice, nodes compete by setting a per-token (or per-inference) price. Meanwhile, developers pick the best combination of cost, performance, and privacy. Higher-tier nodes with top GPUs and TEEs might charge more; smaller nodes might discount heavily to fill idle GPU cycles.
Over time, you get a real-time “spot market” for AI compute. If you’re building a personal research assistant that doesn’t demand super-fast replies, go for cheaper nodes. If you’re building a mission-critical hedge fund strategy, pay more for top-tier, TEE-enabled nodes with high reliability.
#2 — Verification layer
Anyone can claim to run a top-of-the-line DeepSeek R1 with 671M parameters. But how do you confirm they’re not actually sneaking in a smaller, cheaper 8B model to cut their own costs?
The key is verifiability: ensuring the model is correct and executed as advertised.
This is where blockchain shines. Trustless systems, one of crypto’s superpowers, provide verification at a scale that’s otherwise nearly impossible.
Different strategies exist to keep AI outputs reliable, each with its own trade-offs. Two of the most widely discussed approaches are:
Zero-Knowledge Machine Learning (zkML): Every AI inference is mathematically proven before it touches the blockchain. But the downside is it’s painfully slow and resource-intensive, especially for large models. I think of it as the Rolls-Royce of verification: impeccable but pricey.
Optimistic Verification (opML): This approach assumes good intent unless a dispute arises. If flagged, the network resolves the issue by penalising bad actors through stake slashing. While efficient, it relies on active watchers to catch misconduct. The trade-off is a longer resolution period (several days) to allow time for disputes. The motto here is: “Trust, but verify… selectively.”
Confidential Computing
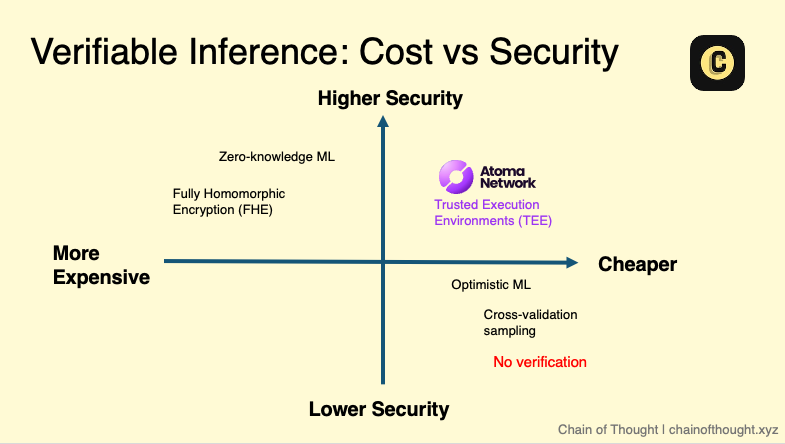
One challenge with the approaches above is the lack of full privacy for model weights and data. This is why Atoma uses Trusted Execution Environments (TEEs) in order to provide truly confidential computing.
You might not trust Google or OpenAI with your data, but you definitely don’t want it processed on someone’s RTX card in their basement.
TEEs aren’t bulletproof, but when distributed across global data centres with randomness, they significantly reduce risks. That’s the sweet spot for decentralised AI.
Confidential computing uses hardware-based TEEs to ensure the integrity of code and the confidentiality of data processed on remote machines. For Atoma, this means proprietary models and personal data can remain confidential, even when distributed across nodes in a decentralised network.
Okay, let’s talk TEEs
If you’ve been exploring Crypto AI, you’ve probably heard of TEEs. But what exactly are TEEs, and why are they such a big deal?
At their core, TEEs safeguard your data by enabling secure, confidential computations.
I like to think of a TEE as a private room in a bustling building—a secure enclave within a processor. The doors stay locked unless you have the right credentials, and once your data and software are inside, they’re effectively invisible to everything else running on the same machine.
Within this secure space, data can be processed without fear of being accessed by other applications, the operating system, or even the hardware administrator. The secret lies in hardware-based isolation, where the security is physically embedded into the chip itself. This makes breaching a TEE extraordinarily difficult, especially for software-only attacks.
TEEs manage encryption and decryption on the fly using specialised hardware features, ensuring robust security with minimal performance overhead. They’ve become a standard feature in next-generation processors and GPUs:
Intel introduced Trusted Domain Extensions (TDX) with its 5th-generation Xeon processors.
AMD includes Secure Encrypted Virtualization and Secure Nested Paging (SEV-SNP) in its EPYC Milan chips.
NVIDIA has integrated TEE-like capabilities into its Hopper GPUs and upcoming Blackwell architectures.
With TEEs, you can run AI tasks in fully encrypted environments. TEEs remove the need to blindly trust cloud services or node operators to keep your data safe.
Atoma’s Full Data Privacy via TEEs
How does Atoma use TEEs in the network?
When users request privacy, Atoma routes their AI computation tasks to execution nodes equipped with TEEs. Only within this trusted enclave can the data be decrypted, processed, and re-encrypted, ensuring that even node operators cannot access it.
Atoma enhances trust through both off-chain and on-chain attestation mechanisms. These attestations are verifiable, hardware-level guarantees that the execution environment behaves as promised.
Let’s explore how on-chain attestation works in practice.
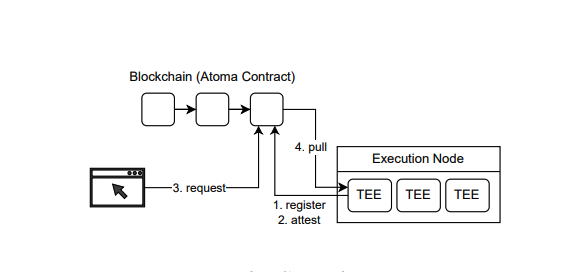
TEE Key Generation and Attestation Report
A node equipped with a TEE generates a unique public and private key pair. It then creates an attestation report that binds the public key to the TEE’s secure environment. The private key is securely stored inside the TEE and never leaves it.
Verification
The attestation report can be verified by an on-chain service, or through an Atoma client. Once validated, the node’s public key is published on the blockchain for all participants to access.
Data Encryption by Users
The user fetches the TEE’s public key from the blockchain, encrypts their input data, and posts the encrypted data back to the blockchain.
Secure Processing by TEE
Only the corresponding TEE instance with the matching private key can decrypt the user’s data. The TEE processes the request securely and encrypts the output using the user’s public key. Hence, there is confidentiality in both sides of the communication.
Output Retrieval
The encrypted output is posted back to the blockchain, where the user retrieves it and decrypts it. For large outputs, a decentralised storage system is employed to securely store and transfer data.
To incentivise privacy-focused infrastructure, node operators are rewarded for offering TEE-capable hardware, with additional compensation for maintaining these capabilities.
The ultimate benefit? Confidential compute. This means user prompts, training data, or proprietary model weights stay private.
Sampling Consensus
Atoma’s toolkit includes a verification mechanism known as sampling consensus, though it now takes a backseat to using TEEs in Atoma’s development roadmap. Atoma can combine TEEs with crypto-economic incentives in a system they call “sampling consensus.”
Atoma’s sampling consensus works by randomly picking a subset of nodes—let’s say 5 or 10—to each run the same inference and return a cryptographic hash of the output. If all hashes match, the result is accepted. If there’s a discrepancy, the network flags it for resolution, penalising dishonest nodes.
The chance that 5–10 random nodes all cheat in the same way is astronomically low unless an attacker controls half (or more) of the entire network’s GPU power. Once the network becomes large enough, this becomes extremely difficult and expensive.
Here’s how it works:
A developer sends a request: “Run Llama3.1-70B with these parameters.”
Atoma’s on-chain logic picks a node
Once the selected node submits the generated output (hash), one or more new nodes will be selected to attest to the first node compute, with some probability 0 < p < 1. Here, p can be less than 0.01 (1%). This can be proved mathematically through a standard game theoretical Nash equilibrium argument.
Each node runs the inference and outputs a hash of the result.
If all hashes match, the result is accepted (and the developer can pay).
If there’s a mismatch, the network triggers a “dispute resolution,” slashing dishonest nodes.
The cool thing about sampling consensus is its “elastic verifiability,” allowing developers to tailor verification levels to specific use cases.
For low-stakes tasks like summarising news, just two nodes might suffice, minimising costs. For high-stakes scenarios like DeFi, scrutiny can scale to 10+ nodes. The math supports this: if verification requires n nodes and p is the proportion of malicious nodes, the probability of a tampered result being accepted is M = p^n
So even with 50% malicious nodes, using 50 nodes reduces the chance of a bad result to near-zero—0.0000000000000000888%.
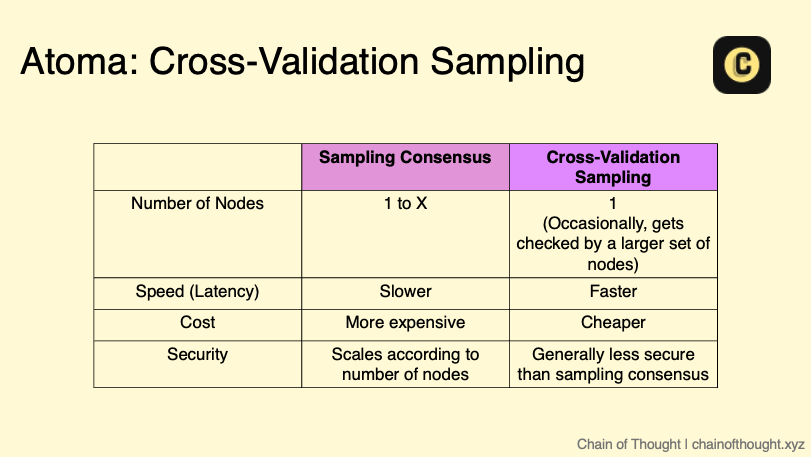
To enhance efficiency, Atoma offers Cross Validation Sampling: most requests are handled by a single node, but periodic cross-checks (triggered probabilistically) involve a larger set of nodes. If the additional nodes agree, the result is validated; if not, the system flags discrepancies.
Assuming malicious control of <50% of the network and node collateral at >250x inference costs, the system achieves stability with only 0.8% of requests requiring replication. This balances trust and cost effectively.
Malicious actors can’t predict when cross-checks will occur, making cheating a high-risk gamble. It’s an ideal solution for low-stakes use cases like gaming or general chatbots. Costs are low enough that this verification can be used all the time.
Of course, if you’re building a high-stakes use case, you might skip cross-validation and replicate every time. Again—elastic verifiability.
Use Cases: What Can You Actually Do on Atoma?

Consumer-Facing Apps
The application layer is where Atoma’s unique verifiability and privacy features shine. Developers can create unique privacy-preserving applications without heavy overheads.
This isn’t just for web3—it applies to any AI-driven application.
Potential apps include:
Personal AI: I would pay good money for a system that learns from my personal data (notes, emails, search history) while maintaining strict privacy. Apple is doing this with its private cloud, and in a big nod towards crypto, its private cloud infrastructure is actually remarkably similar to the design of web3 protocols. Deeper personalisation will unlock the next step up in user experience using AI.
Healthcare: An AI co-pilot for doctors, equipped to analyse personal medical histories and blood test results, offering tailored recommendations and diagnoses. Such a system would support clinicians in making better, faster decisions while ensuring sensitive medical data remains secure.
Data Scraping: Real-time scraping of product prices, stock market data, or metadata from social platforms, with cryptographic verification for every step—collection, parsing, and output. It turns data scraping into a trustable, tamper-proof pipeline for developers and businesses.
Smart Contract–Driven Apps (On-chain Intelligence)
Here’s where it starts getting extra futuristic.
You can have an on-chain protocol request an LLM call. For instance, a DeFi yield aggregator might feed real-time market data to an LLM to decide on an optimal yield strategy. The aggregator’s smart contract calls Atoma’s logic, which picks, say, 5 nodes to compute the best strategy. If they all match, the aggregator updates its yield strategy on-chain.
This opens doors to applications like:
Autonomous Funds: On-chain rebalancing strategies that are both transparent and verified.
Dynamic NFTs: NFTs whose metadata “evolve” based on data interpreted by an LLM (like user achievements or on-chain stats).
DAO Governance: One of the biggest challenges for DAOs is low voter engagement. And I don’t blame voters, it takes a lot of time to participate. AI models could parse proposals, simulate outcomes, and generate recommendations to simplify decision-making, feeding verified results back to the DAO.
Trustless AI on top of a trustless chain.
Private, Trusted AI Agents
I am extremely fascinated by the concept of an autonomous Web3, where AI agents bridge the gap between everyday tasks and self-driving decentralised systems.
AI agents will become embedded in our daily lives.
But they are not transparent at all today. Many agent systems rely on hidden human interventions (think Mechanical Turk-style setups).
Atoma’s decentralised, private infrastructure eliminates this uncertainty, offering fully autonomous agents that can operate with verifiable trust.
As these agents take on more important roles, verifiability becomes non-negotiable. Smart agents powered by Atoma can perform complex tasks: collecting data from oracles, parsing documents, generating transactions, and executing them via contract wallets. These wallets enforce a final permission check, ensuring no malicious node can slip in a fraudulent transaction.
Imagine an agent who evaluates and invests in new protocols on your behalf or a “digital butler” who automatically pays your bills when real-world conditions are met.
Partnership with Sui

Atoma and Sui teaming up is a big deal. It’s two tech stacks coming together to create something fundamentally new.
Decentralized AI needs three things to compete with the centralized giants: speed, scalability, and cost efficiency. Sui delivers all three. As a high-performance L1 built on the Move programming language, it provides the perfect foundation for Atoma’s AI infrastructure.
Now live on Sui’s Mainnet, Atoma can power AI applications as fast and efficient as on Google or OpenAI—but with privacy and decentralization baked in.
Sub-second finality and ultra-low fees make Atoma requests seamless and cost-effective.
Walrus, Sui’s decentralized storage layer, enables private data access. This is critical for advanced AI use cases, particularly those requiring real user ID or wallet-based reputation systems.
zkLogin, Sui’s identity verification system, allows users to authenticate without exposing their credentials, reinforcing Atoma’s trustless AI model.
Backed by advisors from Mysten Labs, Atoma is shaping the future of AI on Sui, helping define what’s possible on the blockchain.
Tokeneconomics
While the details of Atoma’s token design are still being finalised, the overarching framework centres around facilitating platform transactions and incentivising node operators.
Developers pay for AI inferences using TOMA, either on a per-request basis or via token-based subscription packages. This creates direct, scalable demand for the token as AI applications grow across the network.
Node operators stake TOMA as collateral to ensure honest behaviour. This staking mechanism deters malicious actions while securing the network’s integrity.
To sustain network growth and ensure sufficient GPU resources, new TOMA tokens may be issued periodically or distributed from the ecosystem fund as rewards for node operators.
With the global AI market poised for explosive growth, capturing even a small slice of the AI inference economy could generate substantial demand for TOMA, especially if tokenomics are thoughtfully designed to align incentives and drive network expansion.
Roadmap & Future Directives
To recap, Atoma’s roadmap is guided by the 3 key pillars of building decentralised AI infrastructure:
Verifiability
For AI to become humanity’s trusted co-pilot—whether it’s writing code, managing finances, or making critical decisions—it must be transparent, reliable, and provably secure.
Privacy
By leveraging TEEs for end-to-end encryption, Atoma ensures that sensitive data remains private and secure during computation.
Decentralisation
Aggregating GPUs from across the globe democratises access to AI resources, breaking the monopoly of big tech. By creating a decentralised marketplace for AI compute, Atoma envisions greater transparency in pricing and more flexible usage options.
It’s not all smooth sailing.
High-performance GPUs are expensive and scarce, and Atoma’s scalability hinges on attracting specialized nodes. This becomes even trickier with TEEs, where achieving global-scale deployment remains a challenge.
Long-term, Atoma’s ambition is to evolve into a general-purpose compute layer, extending beyond basic AI inference to power high-performance workloads like simulations, rendering, and complex data analysis.
The Team
Source: LinkedIn
The Atoma team has been quietly building for almost 2 years now, long before the recent AI frenzy took centre stage. It’s an intentional effort grounded in a long-term vision for decentralised AI.
Co-founder and CEO Hisham Khan brings a wealth of experience as a serial web3 entrepreneur. His track record includes co-founding Aldrin, a decentralised exchange on Solana that achieved $150M in protocol TVL, and OriginByte, a web3 gaming platform. I’ve had several in-depth conversations with Hisham since early 2024 about the future of decentralised AI, and his thoughtful approach and aligned vision stood out right away.
Co-founder and CTO Jorge Antonio comes from a different world. With a PhD in mathematics, Jorge has deep expertise in zero-knowledge cryptography and machine learning. He is a core contributor at the open-source Plonky3 library, renowned for its speed and efficiency in recursive zero-knowledge cryptography. He was previously at Tari Labs and a core developer of the Cerberus consensus protocol.
The team is lean, with just over 10 members, but it’s a focused, product-first, engineering-heavy group. This disciplined structure ensures that every effort goes into building robust, scalable infrastructure.
Our Thoughts
1. An AI-native blockchain makes a ton of sense
You know, the idea of a Layer 1 blockchain purpose-built for AI is downright sexy to me. (and no, this doesn’t make me question my life choices).
Even on the newer chains, transaction costs add up. It costs $0.02 in gas fees to make a transaction on Sui. That $0.02 will get you ~22,000 tokens on a Llama-3 70B model (on Together.ai).
The blockchains we have today—built around shared, synchronous global states and rigid smart contracts—feel like using a fax machine in a world of instant messaging.
I wonder what if, instead, we had a blockchain designed from the ground up for AI and AI agents, with built-in verifiability? A new kind of L1 where not every transaction is treated the same but instead optimised for AI-specific workloads. Given how frequently inference requests are made, blockchains must be built to accommodate this.
The opportunity is massive. AI-first blockchains wouldn’t just offer AI services—they’d provide compute for training, seamless agent-to-agent communication, and native value transfer. They’d become the default infrastructure for building agentic economies, attracting the very developers shaping AI’s future.
Atoma isn’t the only one chasing this vision, but the upside for a well-designed AI-first blockchain is astronomical. May the best player win—I’ve got a good feeling about Atoma.
2. TEEs are great but not foolproof
Trusted Execution Environments (TEEs) offer strong security for sensitive computations, but they’re far from a one-size-fits-all solution. I see a lot of hype around TEEs as the ultimate fix for verifiable compute, but the reality is more nuanced.
First, TEEs can’t fix bad code. If an application inside the enclave has bugs or intentional backdoors, the TEE won’t magically secure it.
Second, TEEs rely on hardware integrity. They assume the chip itself is flawless, yet even rare design flaws can become attack vectors under the right conditions.
Then there’s the issue of side-channel attacks—where attackers extract sensitive data by analyzing system behaviors like memory access patterns, execution times, or power consumption. That said, these attacks are significantly harder to pull off in machine learning workloads.
Exploiting a TEE is not easy—it requires extensive expertise, resources, and a lot of time. But it’s not impossible, which is why teams relying on TEEs need to stay vigilant.
I like how Atoma tackles these challenges with multi-layered defenses—decentralized node selection, proactive vulnerability patching, and built-in contingency measures. Randomizing node selection, for instance, makes it significantly harder to target high-value data, driving up the cost and complexity of attacks to the point of impracticality.
🌈 Research-level Alpha
Atoma is in its devnet phase, and if you have an NVIDIA-based GPU, you can join as a node operator. Setup takes about 30 minutes, but participation is selective—you’ll need to open a Discord ticket to apply.
While there’s no immediate token or financial incentive, early adopters could see future benefits. The high barrier to entry ensures the network isn’t flooded with bot farmers.
The Atoma Cloud, now in its alpha stage, will receive significant updates in the coming weeks.
If you’re a dev, you can sign up and fund your accounts using testnet USDC, and soon, Stripe integration will enable a frictionless, non-crypto onboarding experience. Once funded, you’ll get API keys and can start building with Atoma’s APIs and SDKs.
The SDK is developer-friendly and OpenAI API-compatible, making it easy to transition from centralized AI backends to Atoma’s decentralized private cloud with minimal code changes.
Also, submissions for the Sui Agent Typhoon hackathon will open this week (31 Jan)!
Atoma is bringing the heat up by powering agents in this hackathon through its API and SDKs. There are $100,000 in prizes up for grabs for those building next-generation AI and Web experiences.
Conclusion
We’re at a pivotal moment. The rapid acceleration of AI is breathtaking, but it also raises concerns about centralisation, data misuse, and unreliable outputs.
Atoma is betting on a different future: decentralized, private, and verifiable AI.
It’s a blueprint for what AI and Crypto can become together. While others are chasing narratives and quick wins, Atoma’s focus on foundational, long-term value may just be its most disruptive move yet.
Thanks for reading,
Teng Yan
This research deep dive was sponsored by Atoma, with Chain of Thought receiving funding for this initiative. All insights and analysis are our own. We uphold strict standards of objectivity in all our viewpoints.
To learn more about our approach to sponsored Deep Dives, please see our note here.
This report is intended solely for educational purposes and does not constitute financial advice. It is not an endorsement to buy or sell assets or make financial decisions. Always conduct your own research and exercise caution when making investment choices.