


Want More? Follow Teng Yan and Chain of Thought on X
Subscribe for timely research and insights—delivered to your inbox.
GM {{ First Name | }}
Surprise! Not one essay this week—but two.
In February, we’re focusing the spotlight on infrastructure projects that are building the foundation for the future of decentralized AI, beyond just AI agents. This essay was co-written with 0xAce.
Enjoy!
TL;DR
Despite record-breaking investments in AI compute, the leap in AI performance has slowed. The AI industry is confronting a new bottleneck: data. In particular, high-quality data—marked by accuracy, deep expertise, and contextual richness.
Pundi AI is decentralizing AI’s most critical layer: training data.
Using on-chain incentives, Pundi AI transforms data labeling and verification into a global, crowd-sourced effort that ensures high-quality data while rewarding contributors.
The Pundi AIFX Omni Layer solves scalability and interoperability challenges by connecting decentralized AI data across multiple blockchains.
With its Data Marketplace, Pundi AI aims to be the “OpenSea for AI data,” empowering developers to buy, sell, and license high-quality datasets.
Between 2022 and 2024, GPUs became the hottest commodity in tech. NVIDIA soared past a trillion-dollar valuation, fueled by an insatiable demand for AI compute. The equation seemed simple:
More compute = better AI.
Pour money into more GPUs, scale up training runs, and watch as AI models get smarter.
And so, the industry has spent over $100 billion on NVIDIA hardware since GPT-4’s training run in late 2022. According to AI scaling laws, that level of investment should have delivered massive performance gains. Historically, doubling computing meant predictable improvements in AI capabilities.
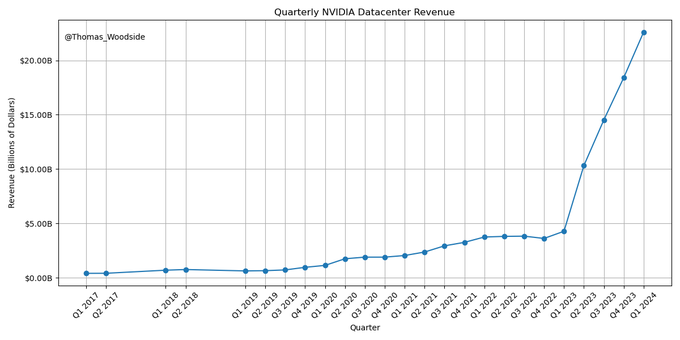
NVIDIA Revenue Spike after Q4 2022 (h/t @Thomas_Woodside)
Yet something strange happened.
Despite the astronomical jump in compute, the gap between GPT-4 and its successors hasn’t widened as much as expected.
Once as reliable as Moore’s Law, the AI scaling “law” is bending, hinting that we may be reaching the limits of what raw computational power alone can achieve.
If throwing more GPUs at the problem isn’t unlocking the next leap forward, what is?
The Data Wall
We are entering an era where data, not compute, is the primary constraint on AI progress.
All the computing power in the world is useless without fresh, high-quality data to train models. And that’s where things are getting tricky.
The challenge is not about collecting more data—it’s about collecting better data.
AI models are starved for training sets that meaningfully improve performance, but those datasets are hard to find, expensive to curate, and riddled with quality issues.
What makes data high-quality?
Deep domain expertise (e.g., medical, legal, scientific knowledge)
Strict labeling standards (inconsistent data poisons models)
Multiple layers of verification (fact-checking at scale is difficult)
Rich contextual metadata (AI needs more than just raw text)
Coverage of edge cases (handling rare but critical scenarios)
And here’s the problem: we may be running out of this data.
OpenAI, DeepMind, and Anthropic are all experimenting with synthetic data generation—using AI to create training data for newer AI models. On paper, it sounds brilliant.
Synthetic data could:
Reduce reliance on human-generated content, avoiding legal and ethical headaches.
Produce massive, customisable datasets at a fraction of the cost.
Fill gaps where real-world data is scarce, like rare medical conditions or niche languages.
But there’s a major risk.
Without stringent quality control, synthetic data could trap AI in a feedback loop—a self-referential echo chamber where models learn from their own flawed outputs rather than fresh, high-fidelity human knowledge.
Left unchecked, this can lead to “AI inbreeding.” Small errors multiply with each iteration, quietly compounding until they cause a steady degradation in model performance. Worst case? Full-on model collapse (this is real, btw)
The Other Data Issue
Data is the new oil—but only a few companies own the refineries.
Think about it – who has the most diverse, high-quality data today?
OpenAI: Massive user interactions through ChatGPT and enterprise deals with media establishments
Google: Search queries, YouTube content, and enterprise data
Meta: Social interactions and content engagement
Microsoft: Enterprise workflows and developer behaviors
This centralization creates a troubling dynamic: the more data they collect, the better their models get. The better their models get, the more users they attract. More users generate even more data.
This self-reinforcing cycle means that AI breakthroughs—and the power that comes with them—are increasingly concentrated in the hands of a few.
The second-order effects are even more concerning. When a handful of companies control the data pipeline, they effectively control:
Which problems AI systems learn to solve
What biases get baked into models
How AI capabilities evolve
Who can build competitive AI systems
This is a societal problem. The data collection capabilities of a few Silicon Valley companies shouldn't dictate the future of AI.
Pundi AI: Decentralizing Training Data
This is where Pundi AI steps onto the stage with a bold proposition: decentralize the most pivotal element of the AI pipeline—training data.
In recent months, we’ve seen major strides in distributing the AI stack:
Compute: Projects like IO, Aethir, and Atoma push GPU power to decentralized networks.
Models: Bittensor experiments with decentralizing AI inference, using incentives to attract miners to solve problems
Yet a crucial gap remains: the data layer.
No matter how “distributed” AI models or compute become, if tech monoliths bottle up all training data, we’re back to square one. Pundi AI’s approach is particularly compelling because it tackles not just data storage but the entire process of data creation and validation.
Conventional data-farm workflows rely on closed-off teams or outsourced labeling shops—scalability lags and misaligned incentives risk tanking quality. Pundi AI flips that model on its head.
Using on-chain incentives, it globally rewards thousands of contributors to label and verify data in real time. This elegantly addresses both scale and quality, transforming the data pipeline from a messy bottleneck into a self-governing ecosystem.
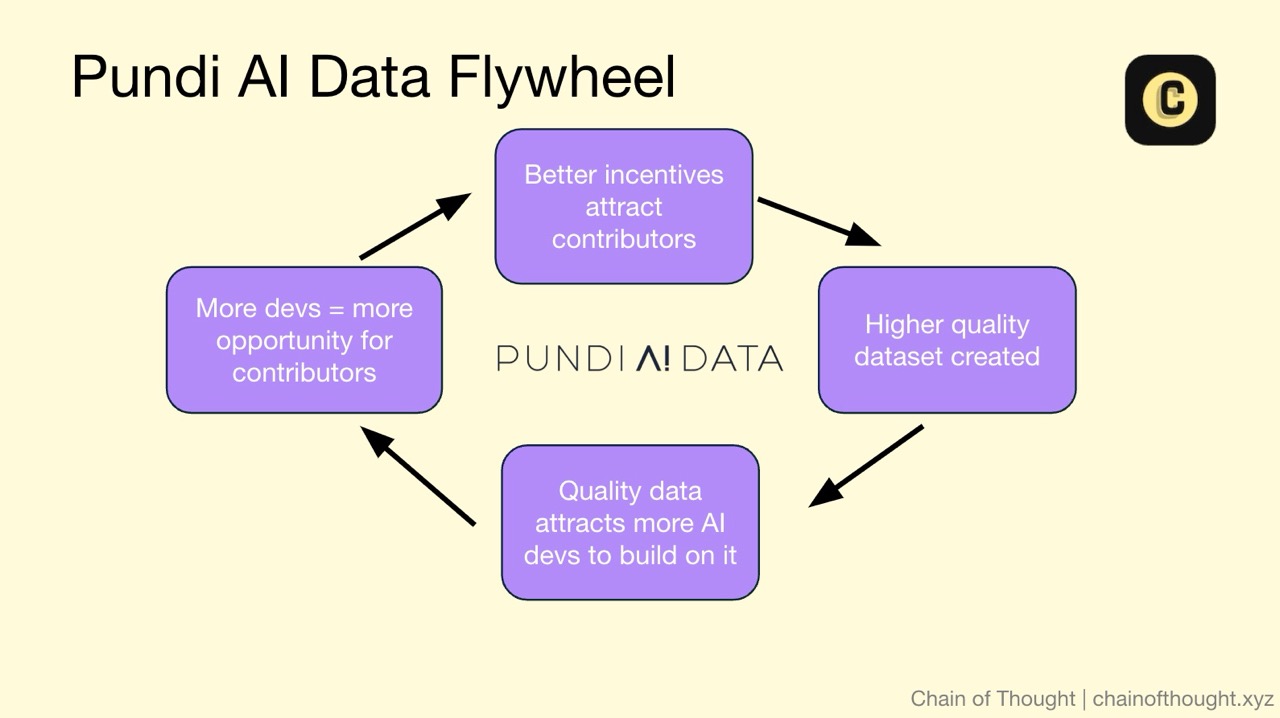
This creates a powerful flywheel effect:
Better incentives attract more diverse contributors
Diverse contributors produce higher-quality, less biased data
Better data attracts more AI developers
More developers create more opportunities for contributors
However, there’s a tricky puzzle in any reward-based data system: participants inevitably optimize for payouts, not necessarily for accuracy.
This often means half-baked labelling, gaming the system, or orchestrated manipulations.
From first principles, real AI decentralization must solve both the data reliability problem AND the incentives puzzle. Failing at either means the entire “decentralized AI” dream remains hostage to centralized data pipelines.
The Pundi AI Ecosystem
Pundi AI aspires to be the foundation for a new kind of AI economy. But to make that vision a reality, it all starts with the data platform.
#1 — Pundi AI Data Platform
Pundi’s data platform needs to solve two fundamental problems:
How to incentivize quality data creation
How to verify that data at scale
The Tag-and-Earn Model
Pundi AI’s tag-and-earn system turns data labeling into an automated ecosystem where contributors are rewarded for their efforts, and quality control is baked into the process.
What makes Pundi Ai’s model work is the way it creates alignment between different players in the ecosystem:
Data Providers (companies, researchers, or individuals) upload raw or partially processed data. Tasks can range from text classification and image labeling to complex entity recognition and bounding-box annotations.
Annotators (Data Processors) pick tasks and label them in exchange for rewards, with all tasks and outputs recorded on-chain to ensure transparency.
Reviewers (Data Verifiers) verify the quality of annotations. They’re incentivized to flag low-quality work, keeping the system free of spam and ensuring datasets maintain high accuracy.
Once a majority consensus is reached, the dataset is validated, aggregated, and either sold to data buyers or made open-source.
So instead of relying on a centralized review process as with companies like Scale AI, Pundi AI distributes validation across multiple participants, creating a decentralized reputation system where bad actors get filtered out, and high-quality work is consistently rewarded.

Using the Data Platform
The platform is currently available on testnet on a whitelisted basis (apply here) and the contribution process looks very straightforward.
You begin by connecting your wallet and exploring the available tasks. The platform displays your potential earnings in both testnet USDT and FX tokens, making it easy to understand the rewards for your contributions.
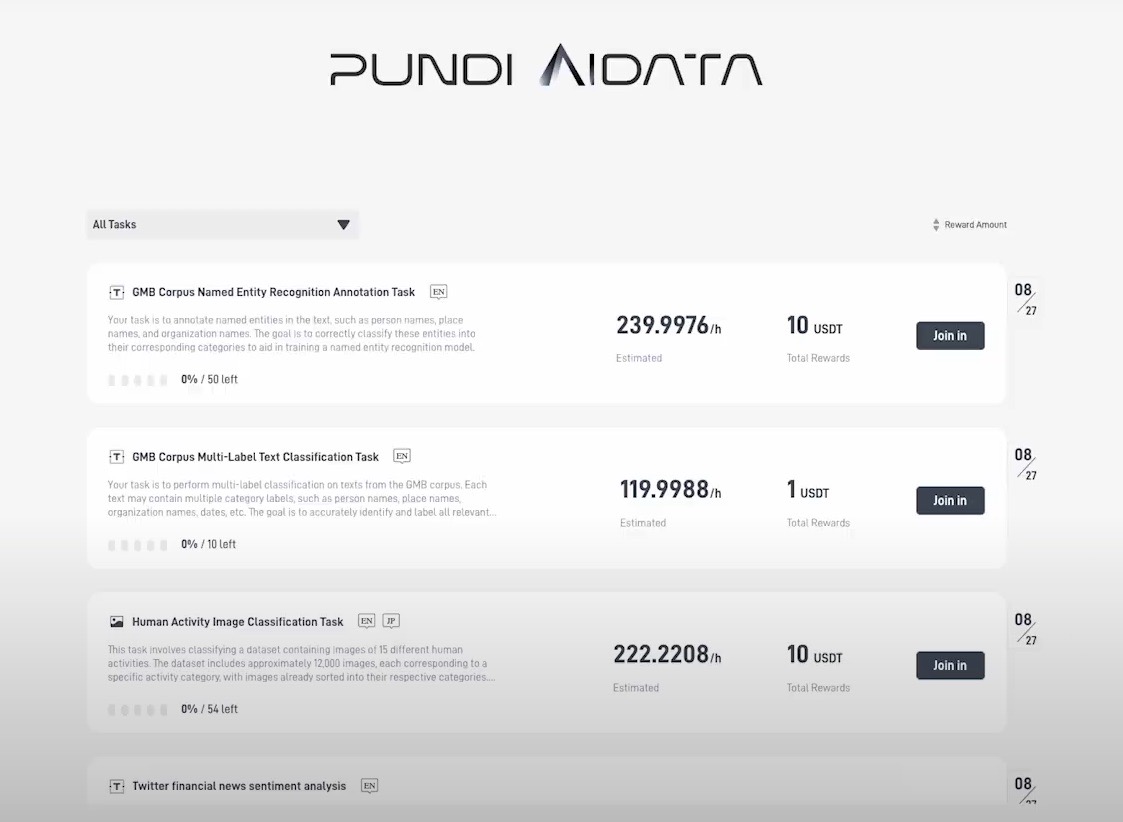
Take the Human Activity Image Classification task.
After selecting the task, you're immediately presented with a clean interface showing images of people performing various actions. Each image comes with multiple classification options, and the platform guides you through selecting the most appropriate one.
Each correct classification adds to your earnings, which accumulate in real-time as you work.
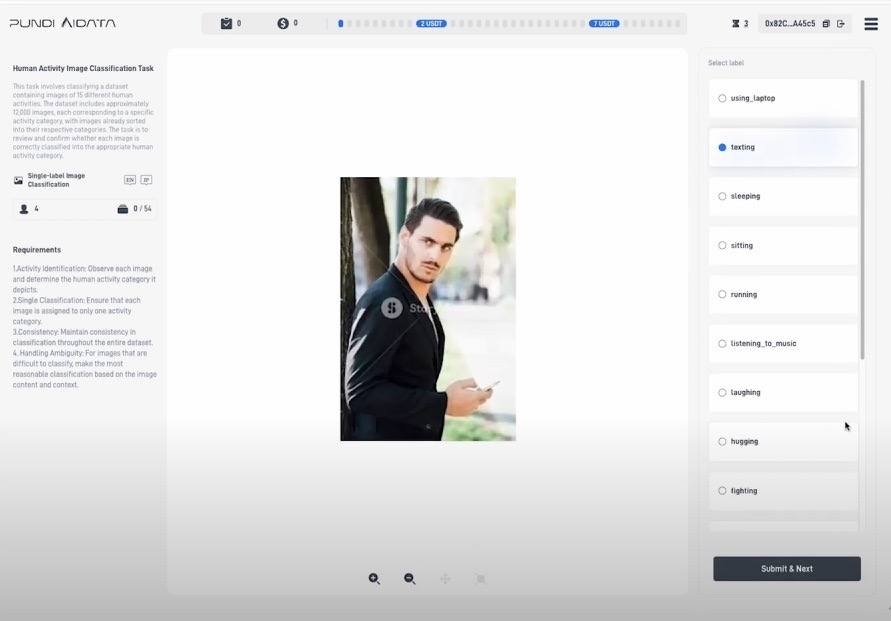
Data Quality Control
Quality control is built into the workflow. Your labeled data goes through multiple reviewers who rate the accuracy on a scale of 1-5.
The platform requires three independent reviewers to verify each piece of data, ensuring high standards while keeping the process moving.
For rewards distribution, you'll receive your earnings once your work passes the verification process. The platform handles this automatically, with verified results triggering a transfer to your connected wallet. The task interface shows your progress and accuracy metrics.
We found it motivating to see your contribution count rise and your reputation score improve as you complete more tasks accurately.
So, the platform breaks down complex validations into smaller, verifiable tasks.
Each piece of data goes through multiple validation layers, from basic quality checks to thorough review and consensus verification.
Another interesting aspect of the platform is that every piece of content is tracked on-chain through NFTs, with tag content encrypted jointly by the uploader and the contract.
The data itself lives on IPFS, while verification proofs and access controls are managed through smart contracts.
This creates an immutable record of data provenance– who created it, how it was verified, and who has access rights. It's a simple but powerful solution to the trust and quality issues.
#2 — The Infrastructure Challenge: Pundi AIFX Omni Layer
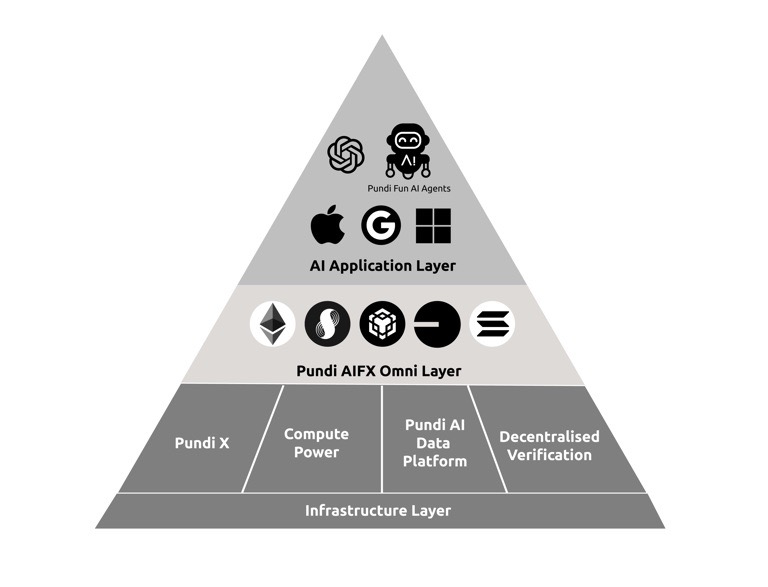
No matter how sophisticated the data-labelling scheme, if the underlying chain can’t handle the scale or the complexities of bridging multiple blockchains, the system caps out. That’s where Pundi AIFX (the omnilayer) comes in.
Think about it– the AI ecosystem is inherently fragmented:
Data lives on various chains and storage solutions
AI models run on different platforms
Users want to interact through their preferred networks
Traditional cross-chain solutions weren't built with AI workloads in mind. They're optimized for value transfers and basic message passing, not the complex data flows and compute requirements of AI systems.
Every component here plays a distinct role in making AI data systems trustworthy, efficient, and interconnected. On-chain verification proofs ensure every piece of labeled data is permanently recorded and auditable.
At the same time, Pundi AIFX is EVM-compatible, meaning it natively supports Ethereum-based smart contracts.
Verification proofs and programmable access controls are handled on-chain, ensuring secure, transparent, and permissioned AI data processing.
And because AI applications aren’t confined to a single blockchain, Pundi AIFX connects to ecosystems like Base and Cosmos. This means a developer can store data on Base while still leveraging Pundi AI’s labeling architecture—without dealing with the headaches of cross-chain orchestration.
f(x)Core is Pundi AIFX’s execution layer. Built on a modified Tendermint consensus with EVM compatibility, it acts as the bridge between AI workloads and blockchains.
When an AI model or application needs to fetch, process, or verify data, f(x)Core’s modified pBFT (Practical Byzantine Fault Tolerance) consensus layer ensures requests are validated, synchronises state across multiple chains, and maintains consistent data availability.
IBC protocols handle cross-chain message routing, ensuring smooth interoperability between blockchains. Smart contracts manage access control and verification proofs, providing a secure, programmable framework for AI data rights management.
Alright, that’s a whole mouthful of technical geek talk… sorry!
What’s most important to note is that all of this complexity stays behind the scenes. It is abstracted away through a simple, developer-friendly API, allowing developers to integrate AI-driven data validation and retrieval without dealing with the intricacies of cross-chain orchestration.
AI training and annotation workflows generate a torrent of microtransactions—every labeled data point, every verification, and every reward distribution is effectively a blockchain event.
This requires a network capable of handling high-throughput, low-latency transactions. Pundi AIFX’s pBFT consensus can handle heavy workloads, with transactions are confirmed quickly and efficiently.
Building on Base
Pundi AIFX is launching with Base ecosystem support first—a strategic decision that places it at the intersection of two accelerating trends:
The growing ecosystem of AI and agent-based infrastructure on Base, particularly with platforms like Virtuals and Creator Bid gaining traction.
The rapid adoption of Layer 2 solutions, where scalability and cost-efficiency are driving mass migration from Ethereum’s mainnet.
A major reason for Pundi AIFX’s focus on EVM support is simple: data monetisation and AI marketplaces are already deeply embedded in the EVM ecosystem. DeFi protocols, NFT-based data markets, and AI-driven financial applications still operate predominantly on Ethereum-compatible networks.
By ensuring native EVM integration, Pundi AIFX makes it easy for participants to create, trade, and leverage “Data NFTs” and AI-driven assets within the same ecosystem.
#3 — The Pundi AI Data Marketplace
Data is everywhere, but true data markets? Not so much. Right now, data mostly changes hands in closed-door deals or gets sold via API access.
Pundi AI wants to change that by launching a full-scale Data Marketplace—an open exchange where AI developers and enterprises can buy, sell, and license high-quality datasets.
These include:
Untrained data: raw images, text corpora, or domain sets that haven’t been curated or labeled extensively.
Partially labeled data: already run through the Pundi AI Data platform’s pipeline or partially annotated by experts.
Fully curated sets: verified with a high aggregator rating.
Trained models: Ready-to-use AI models that dataset owners can license as “trained checkpoints.”

The marketplace would effectively become the “OpenSea” of data.
Developers can browse datasets, verify their provenance on-chain, check how they were tagged and validated, and review any usage disclaimers (for example, restrictions on medical data). Once they find what they need, they can purchase access using ecosystem tokens, unlocking the dataset or securing a licensing agreement.
Everything on the marketplace comes with a transparent provenance record, showing validation history, quality metrics, and contributor credibility. NFT-based tracking and smart contracts ensure secure transactions.
For buyers, this means verifiable, high-quality data without the guesswork. For sellers, it’s a way to monetize intellectual property while maintaining control over their data.
By bridging the gap between data creation and commercialization, Pundi AI is turning AI training data into a liquid asset.
The data marketplace testnet is expected to go live in Q2.
#4 — Pundi AI Fun & AI Agents
Pundi AI is also hinting at something bigger on the horizon: an “agentic AI agent” that could be trained directly within its data platform. The details are teased as a 2025 launch, but the concept is that you can:
Pull data from the marketplace,
Feed it into an on-chain agent training environment,
Spin up an autonomous AI agent—potentially governed by tokens or a DAO.
While the exact mechanics remain in the pipeline, the big idea is that the chain wouldn’t just store or label data. Instead, it will be a system where users can mint “mini-AIs” that run on-chain. (”Pundi Fun, an AI agent launcher”)
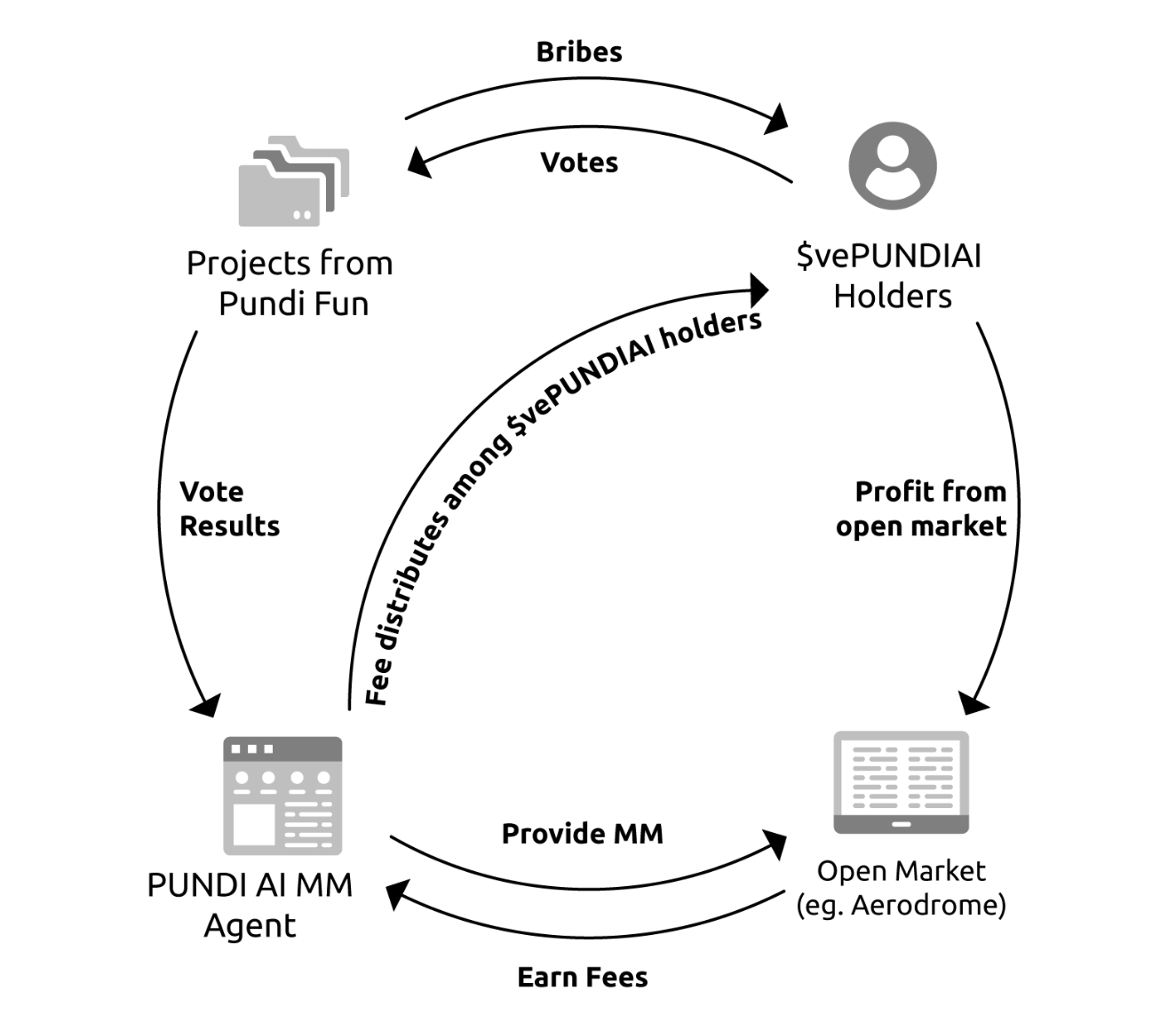
The Agent Launcher intends to introduce a “Protocol Wars” dynamic reminiscent of DeFi’s Curve Wars. AI projects will be able to incentivize $vePUNDIAI holders with bribes to vote for their agent tokens, influencing liquidity allocation and visibility on the platform.
AI projects launch agent tokens on Pundi AI’s platform, where they can incentivize $vePUNDIAI holders with bribes to secure votes. These votes directly impact liquidity allocation and protocol incentives for each agent. The more votes an agent receives, the more liquidity support and visibility it gains from the protocol.
If successful, this mechanism could create significant token demand, as AI projects compete for influence.
This hints at a future where Autonomous AIs are co-owned by data contributors, validated on-chain, and even integrated into financial markets. These agents might play an active role in market making, DeFi automation, or even data economy orchestration, turning AI into an on-chain labor force.
The Full Stack Approach
Pundi AI is constructing an integrated AI ecosystem that connects every step of decentralized AI development, from data creation to AI agent deployment.
Here’s how it all fits together:
The Data Platform is the foundation, where a global network of contributors generates, validates, and curates AI training data—both raw and trained—verifiable on-chain and ready for use.
The Omni Layer ensures seamless access to this data across blockchains, starting with Base.
The Data Marketplace enables direct transactions between data creators and buyers, streamlining AI data commerce.
Quality data flows through the omni layer, gets packaged in the marketplace, and powers the next generation of AI agents.
This integration creates an ecosystem where better data enables more sophisticated agents, leading to increased data usage and value for contributors. As more contributors join, data quality and diversity improve further, accelerating AI development across the platform.
Tokenomics
The Pundi team isn’t new to crypto.
The team has been building in the space for years under Function X, facilitating decentralized payments using the $FX token. Launched in 2019, $FX is a battle-tested asset, currently trading at a ~$100M fully-diluted valuation.
Instead of launching a new token, Pundi AI is leveraging this existing ecosystem by redenominating its FX token to PUNDIAI on 25th February, 10AM (GMT+8).
There will be no new tokens minted (thankfully) and it will be a 100:1 conversion, with 100 FX becoming 1 PUNDIAI.
This rebranding could be a strategic move.
Crypto cycles survived: The token has already weathered multiple market fluctuations.
Loyal holder base: 61% of the circulating supply (476M of 784M tokens) is already staked and delegated, signaling strong conviction. There is a competitive 15% APR for delegation.
No VC overhead: Unlike many newer projects, there’s no looming venture capital sell pressure.
With a built-in base of committed supporters, Pundi AI starts its AI data expansion from a position of strength.
Token holders gain substantial influence over platform development through the delegation and vote-escrow system. PUNDIAI will function as a dual-token model to incentivize data providers, verifiers, and processors:
PUNDIAI – Liquid utility token used for transactions.
vePUNDIAI – Vote-escrowed token that aligns long-term incentives, similar to Curve’s ve token mechanics. The system allows for up to 4-year locks.
Converting PUNDIAI to vePUNDIAI enables participation in governance decisions, with voting power increasing based on lock duration.
vePUNDIAI holders receive additional rewards through protocol fee sharing and potential bribes from AI agent launchers through Pundi Fun.
Revenue Model
Protocol revenue is generated through multiple streams:
10% fee on marketplace transactions
Infrastructure fees from AIFX layer
AI agent launch fees (when the AI Agent Launcher goes live)
All revenue flows into a protocol pool, funding rewards, development, and ecosystem expansion.
Our Thoughts on Pundi AI
1. Competing with Scale AI? Not Quite—And That’s a Good Thing
At first glance, it’s tempting to compare Pundi AI to Scale AI—the $7.3B behemoth and undisputed heavyweight in AI training data.
You might think: no way Pundi AI stands a chance.
But that’s the wrong lens. Pundi AI isn’t trying to go toe-to-toe with Scale AI, and that’s precisely its edge.
Scale AI has fortified its position in enterprise AI data services, building deep relationships with tech giants like OpenAI, Microsoft, and Apple. Their strength lies in highly structured, large-scale data annotation pipelines, rigorous quality control, and deep integrations into existing AI workflows.
Pundi AI, on the other hand, is playing a different game:
Targeting smaller AI teams & specialized models. These include Web3 AI agents and domain-specific AI models that often struggle to source niche, high-quality training data—a gap Scale AI isn’t built to fill.
Expanding into open-verified datasets. Unlike centralized providers, Pundi AI’s decentralized validation model could be ideal for sensitive, high-stakes AI models, where transparency and accuracy are critical.
Take medical AI as an example: Pundi AI is working with a medical device company to build training data for AI models that interpret device displays in real hospital settings. This kind of high-stakes dataset—where accuracy impacts patient care—requires expert validation and meticulous labeling.
Traditional AI data providers often overlook these niche but high-value datasets, but Pundi AI’s community-driven validation system is well-suited for the task.
Instead of trying to beat Scale AI, Pundi AI’s best path is to expand the market in a way centralized players can’t easily follow.
2. The Data-Agent Flywheel: A Self-Reinforcing Model
Most AI agents in crypto today—whether Virtual’s GAME, Eliza OS, or others—pull from the same, limited data sources. Their reasoning has evolved past simple if-else logic, but without diverse, high-quality training data, their intelligence remains capped.
Pundi AI’s approach could break this bottleneck. By integrating a high-quality data marketplace with an agent launcher, they enable a reinforcing cycle:
Better data leads to more sophisticated AI agents.
More advanced agents attract more developers and users.
Higher demand for quality data incentivizes more contributions.
This flywheel effect is a powerful differentiator. The more data gets refined and validated on-chain, the better AI agents become.
3. Focus & Chain Expansion: Execution is Everything
Base Is a good start, But Solana could be the next battleground
Pundi AI’s decision to launch on Base makes sense—it was early to the AI agent trend and has strong developer momentum. But Solana is also pulling ahead in AI agents, and that’s a problem if ignored.
Solana has outpaced Base in agent liquidity and developer mindshare.
More projects are integrating AI models into Solana’s high-speed infrastructure, creating network effects that are hard to ignore.
Thinking carefully about where users and developers are while being agile will be key to Pundi AI’s long-term success.
Also, a common startup pitfall—one I’ve faced firsthand—is too many ideas, not enough resources. With limited engineering and business capacity, you always have to be ruthless about which ideas you want to pursue at any one time.
Pundi AI is tackling multiple complex products simultaneously—a data marketplace, AI agent launcher, on-chain training, and governance. Each of these demands deep technical execution, iteration, and market adoption.
One risk that Pundi AI could face is a lack of focus. Instead of scaling too broadly too soon, Pundi AI would benefit from delivering one core product exceptionally well—whether it’s the data marketplace or agent launcher—before expanding.
Pundi AI has a strong vision, but execution will determine if it becomes foundational AI infrastructure or just another ambitious experiment.
Conclusion
Pundi AI is tackling a real pain point in AI: access to high-quality, verifiable training data. By combining a decentralized data marketplace with an AI agent launcher, it’s positioning itself as a core piece of infrastructure for the next wave of AI development. The potential is massive, but so are the execution risks.
Success won’t come from vision alone. Pundi AI must bootstrap high-quality data, sustain buyer demand, navigate regulatory landmines, and carve out a niche against centralized incumbents. None of that is easy.
The big question is whether AI companies will actually turn to decentralized markets for training data.
If they do, Pundi AI has a real shot at becoming the foundational infrastructure for AI’s decentralized future.
Cheers,
Teng Yan & 0xAce
Useful Links
This deep dive is done in collaboration with Pundi AI, with Chain of Thought receiving a small cash grant for this initiative. All insights and analysis are our own. We uphold strict standards of objectivity in all our viewpoints.
To learn more about our approach to sponsored Deep Dives, please see our note here.
This report is intended solely for educational purposes and does not constitute financial advice. It is not an endorsement to buy or sell assets or make financial decisions. Always conduct your own research and exercise caution when making investment choices.