


Want More? Follow Teng Yan & Chain of Thought on X
Subscribe for timely research and insights delivered to your inbox.
TL;DR
The rapid growth of AI agents is leading to clutter and confusion, similar to the early days of the App Store. Quality is hard to assess until after users have already spent time testing agents.
Recall is building a decentralized reputation protocol where agents earn credibility by competing in live, on-chain challenges such as trading, coding, and forecasting.
AgentRank, Recall’s core reputation system, is based on three factors: verifiable competition results, economic conviction from token-staking curators, and consistent performance over time.
The protocol has early momentum, with over 1 million testnet transactions, 276,000 accounts, and high-participation competitions like AlphaWave. Agents like Moonsage Alpha have demonstrated strong performance across multiple events.
The long-term goal is to make AgentRank the default discovery layer for the autonomous internet, helping agents find trustworthy collaborators and enabling users to rely on performance data instead of marketing claims.
One of the first apps I ever downloaded on my phone was Talking Tom the Cat.
The dead-eyed feline who parroted back whatever you said in a high-pitched squeal.
I’d feed Tom the dumbest lines I could think of, then replay them to my friends like I was doing stand-up. It was glitchy, pointless, and completely addictive.
Then came the clones.
Talking Angela, Talking Ginger, Talking Ben, Talking Dog, Talking Robber. I think there was even a Talking Toilet at one point. Every few months, a new “talking” app popped up, and naturally, I had to try them all.

From Talking Tom And Friends
I still remember one in particular, I don’t even remember the name, just that it was awful. Ads every two seconds. No voice detection. Animations that looked stitched together in PowerPoint. That’s when it hit me: making apps had become too easy. And the result wasn’t more creativity. It was more copies.
But that’s what happens when creation gets easy: proliferation becomes the new problem.
Every now and then you stumble upon something genuinely clever but most are garbage. The worst part? You don’t know it sucks until you’ve already tapped “install.” That’s the real tax: wasted time, wasted attention.
Now zoom out. AI agents are the new Talking Tom. The barrier to entry is lower than ever, and the clones are coming. Faster, buggier, and way more consequential.
This is exactly the kind of mess Recall is trying to make sense of. By creating an open, on-chain arena where agents compete, rank, and actually have to prove they do something.
Could Recall be the Google of the AI agent era? Let’s explore.
An Internet Full of Unproven Intelligence
The Internet is getting a brain.
Not just smarter interfaces or faster search. Actual autonomous agents. They’re handling portfolios, writing blogs, booking trips, even diagnosing your weird elbow rash.
This is the rise of the Internet of Agents. A whole new strata of digital life. By 2034, it’s projected to drive over $200 billion in value. That’s a 30x jump. The scale is nuts.

But there’s a catch. A big one.
Nobody knows which of these agents actually work.
The floodgates are open. Open-source frameworks and drag-and-drop agent kits mean anyone can spin up a chatbot with a slick UI and a sales pitch. The result? A Cambrian explosion of indistinguishable agents making big claims and delivering god-knows-what.
We don’t have too few agents. We have too little trust.
Take crypto trading agents. There are dozens in the Virtuals ecosystem alone. All promise alpha.

Source: Virtuals.io
But with no shared benchmarks, no performance proofs, no transparency into how they reason or learn, you’re choosing based on vibes. Maybe a GitHub link. Maybe a tweet. The whole discovery process runs through the “For You” page.
That’s the real bottleneck. Discovery has become a popularity contest. Virality is standing in for intelligence. If an agent looks cool in a 15-second demo, it wins. The algorithm is picking your tools now.
Strong agents get buried if they don’t meme well. Without trusted discovery mechanisms, we risk underutilizing truly capable agents while wasting time and capital on poor-performing ones.
This isn’t new. Early web discovery was the same. You found sites through webrings, blogrolls, or whatever your cousin emailed you. Then PageRank changed everything. Suddenly, links became signals. Credibility was earned, not guessed. And discovery got smarter.
We sorely need a PageRank for agents.
Unless we develop a system that evaluates performance, tracks reputation, and enables trusted discovery, we risk building an agentic internet that’s chaotic and fundamentally untrustworthy.
A protocol for evaluating what works and tracking real-world performance. Without that, the agentic internet won’t scale. It’ll splinter.
Enter Recall: Where AI Fights for Its Life (Literally)
That’s exactly what Recall is building.
Rather than relying only on marketing or social virality, Recall introduces a new paradigm: agents must prove themselves. In public. Under pressure. And onchain.
Recall is a decentralized, cryptoeconomically-secured infrastructure that brings accountability, reputation, and merit-based discovery to AI agents. It’s a performance arena, a reputation layer, and a coordination engine, all rolled into one.
At its core, Recall offers:
Agent Rank: A reputation protocol that scores agents based on verified performance and economic backing. PageRank, but for AI.
Onchain competitions: Agents go head-to-head in live skill-based challenges—trading, coding, predictions, etc.—with verifiable, immutable results.
Staking and curation: Participants stake tokens on agents they believe will perform well, earning rewards if they're right, and facing slashing if not.
Skill pools: Crowdsourced demand signals for which agent skills are needed most, aligning AI development with real-world use cases.
With these components working together, Recall creates a system where agents compete, improve, and earn trust over time. In other words, Recall is where the best agents rise to the top because they proved they deserved to.

How It Works: From Code to Credibility
From the moment an agent is written, everything that happens is recorded, evaluated, and used to build a public, on-chain reputation.
Here’s a breakdown of how the entire process works:
1. Building Agents: Fast, Flexible, and Framework-Agnostic
Everything starts with the developer, whether it’s an indie builder, a research team, or a DAO deploying agents at scale.
Agents are built using the Recall Agent Toolkit, which integrates easily with existing AI frameworks like:
LangChain
OpenAI Assistants
Mastra
Letta
Any MCP–compatible stack
This means agents can be constructed using familiar developer tools, but with built-in access to:
Persistent memory (via Recall’s Bucket system)
Participation in live competitions
Standardized interaction protocols
Once registered, the agent becomes an autonomous identity on the Recall Network, ready to act, learn, and compete.

Source: Recall Docs
2. Competing: Where Performance is Public
Agents participate in live, on-chain competitions that simulate real-world tasks like trading, prediction, summarization, decision-making, and more. These challenges are designed to be high-signal and stress-tested in messy environments where strategy, speed, and adaptability matter.
A good example of this is their inaugural trading agent competition called AlphaWave, a 7-day crypto trading tournament where 25 agents managed virtual portfolios. Each started with $30,000 and was ranked by real-time profit and loss.
The winner, Moonsage Alpha, not only generated the most revenue but also transparently logged each trade and decision on-chain, earning both top marks and public trust.

Source: AlphaWave
In these competitions:
Agents interact with standardized APIs tied to the challenge
Their decisions and outputs are automatically evaluated using preset metrics (e.g., ROI, accuracy, latency)
Optional subjective scoring (e.g., reasoning quality) can be done by other agents or human moderators
Every action will be recorded on-chain for auditability and replay
So, these competitions are persistent signal generators that power Recall’s broader trust infrastructure.
3. Memory: Agents That Learn and Remember
Recall agents can also store, retrieve, and evolve over time using the protocol’s Bucket system.
Think of Buckets as:
Cryptographically secured storage units, linked to each agent
Repositories for things like reasoning traces, historical performance data, prompt chains, or learned preferences
Agents can write to their Buckets in real time, and depending on permissions, other agents can access those same Buckets to collaborate or analyze past behavior.
For example:
A trading agent might store price-action patterns it’s observed over time
A research assistant could keep a long-term memory of key sources or conclusions
A decision agent could refine its risk logic across use cases
All of this happens natively on Recall, meaning the state of an agent is verifiable and persistent.
This is important because it enables agents to learn over time, justifying their decisions, and interoperating with other agents through shared memory. It turns ephemeral bots into reliable, composable building blocks for machine coordination.
While many agents today already use off-chain databases like Postgres or vector stores (e.g. Pinecone) to implement memory, these setups are usually siloed and tightly coupled to the developer's stack.
Recall’s Bucket system offers a shared, permissioned memory layer that’s verifiable and portable across agents, with minimal integration overhead. It abstracts away the need for custom backend plumbing, allowing builders to plug in persistent memory natively without sacrificing auditability or interoperability.
In short, it's memory made modular, transparent, and agent-friendly by default.

Source: Recall Docs
4. Evaluation and Scoring: Trustless Performance Data
Every action an agent takes, like a trade, prediction, or decision, is evaluated and logged.
There are two key evaluation modes:
Objective: Metrics like ROI, speed, correctness, and coverage are scored automatically.
Subjective: For creative or interpretive tasks, Recall can support human or peer-agent review, with built-in consensus and scoring protocols.
Evaluations are then:
Anchored to block timestamps
Stored immutably on-chain
Linked to the specific competition and task environment
This creates a transparent trail of agent behavior. It eliminates the need for screenshots or unverifiable “demos.”
Building Reputation: AgentRank
Trust, in autonomous systems, can’t be an afterthought. It has to be structural. For Recall, that structure is AgentRank.
At a high level, AgentRank turns performance into reputation. It’s a score, but also a record. A traceable, evolving map of how well an agent operates within specific domains. The goal is to surface the most capable agent for a given task, in real time, with verifiable backing.
But how exactly is AgentRank calculated?
AgentRank draws from three core inputs, each designed to balance technical performance with market signal:
Performance: What Did the Agent Actually Do?
This is the most fundamental layer. Since every action and result is logged during competitions, AgentRank uses that on-chain performance data as a core input.
AgentRank analyzes:
Outcome metrics like profit/loss, accuracy, or latency
Task type and difficulty
Relative performance compared to peers (e.g., percentile or Z-score)
These scores are then normalized and categorized by skill domain, allowing agents to build reputations in specific areas (e.g., high AgentRank in DeFi, lower in NLP), rather than being treated as general-purpose black boxes.
Importantly, recent results in competitions are weighted more heavily than older ones. This helps account for agents that evolve over time, whether by updating their prompt, model, or logic. If changes cause performance to degrade, it gets picked up in future competitions. Agents can’t coast along on past results. They need to keep competing to maintain their score.
Conviction: Who Believes in This Agent?
The second layer is more social, but still economic. Users can stake on agents they believe in, domain by domain. The earlier they stake, and the more accurate their past bets, the more that signal matters.
It’s a system inspired by curation markets, but tuned to avoid the obvious failure modes. Conviction can amplify a good track record, but it can’t paper over a bad one. Scores are bounded. Hype alone can’t carry an agent past the limits of what it’s actually done.
Conviction is calculated using:
Total stake behind an agent in a skill-specific pool
How early that stake was applied (earlier curators get more credit)
Historical accuracy of curators (i.e., did this curator have a good track record?)
Decay over time (if the agent stops competing or if curators stop renewing conviction)
Conviction helps in two ways: it bootstraps reputation for new agents and it reinforces trust in those that consistently perform. It’s a forward-looking signal layered on top of historical proof.
Consistency: Can This Agent Be Trusted Over Time?
A single win doesn’t build trust. Sustained, stable output does.
Consistency is computed as:
Number of competitions entered within a rolling time window
Variance in performance (e.g., is the agent always in the top 10% or fluctuating?)
Task diversity: how well the agent generalizes across similar but non-identical challenges
AgentRank favors consistent participation. Agents that go inactive will gradually lose visibility or fall behind peers who continue to perform.
AgentRank = A Composite, Transparent Score
Putting it together, AgentRank is a weighted synthesis of:
Verifiable competition results (on-chain)
Curator stake and conviction (economic signal)
Historical consistency and participation (temporal stability)
It’s verifiable (based on on-chain data), queryable (for agents, humans, or apps), and composable (usable across tasks and systems).
It’s also transparent. Anyone can ask: “Who are the top 3 DeFi agents over the last month, with low variance and high curator confidence?” You can’t fake that with influencer marketing.
It’s an ELO-style dynamic system, like chess ratings, but for autonomous intelligence. If an agent crushes one contest and then disappears, its score gets stale. As newer agents compete and rack up results, the inactive ones drift downward.
What Happens When the Agent Evolves?
A core challenge with any reputation system for AI agents is that agents are rarely static. They’re constantly evolving. Changing prompts, updating models, and retraining on new data. That flexibility is part of their power, but it also creates a moving target for evaluation.
If an agent updates its logic, past performance may no longer reflect current capabilities. Worse, performance degradation could emerge slowly, only showing up after several new competitions. This raises important questions for Recall:
How does the protocol detect or account for regressions after updates?
Can developers version agents and reset or fork AgentRank if they change core functionality?
Will there be incentives or requirements for agents to re-enter certain benchmark competitions periodically?
As of now, the design assumes reputation is earned continuously, meaning agents that stagnate or regress will naturally fall in rankings over time. But version control or change-tracking could become necessary infrastructure as agents grow more complex.
Early Traction and Demand
Recall’s still young. But its March 2025 testnet launch offered the first glimpse into a working layer where agents compete and get judged in public.
Here’s what’s happened so far:
1 million transactions
276,000 unique accounts
100,000+ intelligence blobs logged onchain
A large portion of these early transactions were low-level operations: token transfers, data-storage operations, and agent-profile registrations. That said, we’re now seeing much more meaningful interactions emerge on top of that foundation:
Over 225,000 curator votes cast inside live agent competitions so far
Hundreds of agents signed up and are actively participating
Some of this growth is incentive-driven. People expect airdrops. They speculate. That’s normal. But the builder participation and voting activity suggest that many users are genuinely exploring what it means to build, back, and benchmark autonomous agents in a transparent way.
As more of Recall’s competition mechanics and agent actions move fully on-chain, these numbers will likely evolve into a much clearer picture of persistent demand.
Competition #1: AlphaWave
Recall’s debut contest, AlphaWave, focused on DeFi trading agents. It was meant to test both the infrastructure and the appetite. Over 1,000 teams applied. Not bad for a protocol barely a month old.
But it wasn’t only builders who showed up. There was also a fan vote that acted as a kind of test run for Recall’s future curation markets, tapping into social sentiment to spotlight favored agents, without requiring any staking.
141,888 users across six continents cast their votes, making it the largest AI agent competition ever held. That level of attention for a crypto-native, open agent arena was unprecedented.
Competition #2: ETH vs SOL
The follow-up event, ETH vs SOL, tightened the format. Ten trading agents. $25,000 in starting capital. This round drew even more attention:
356,000 total votes
Moonsage Alpha won agent of the tournament with 45% of the vote
ETH-aligned agents won the crowd’s trust with 70% of total support
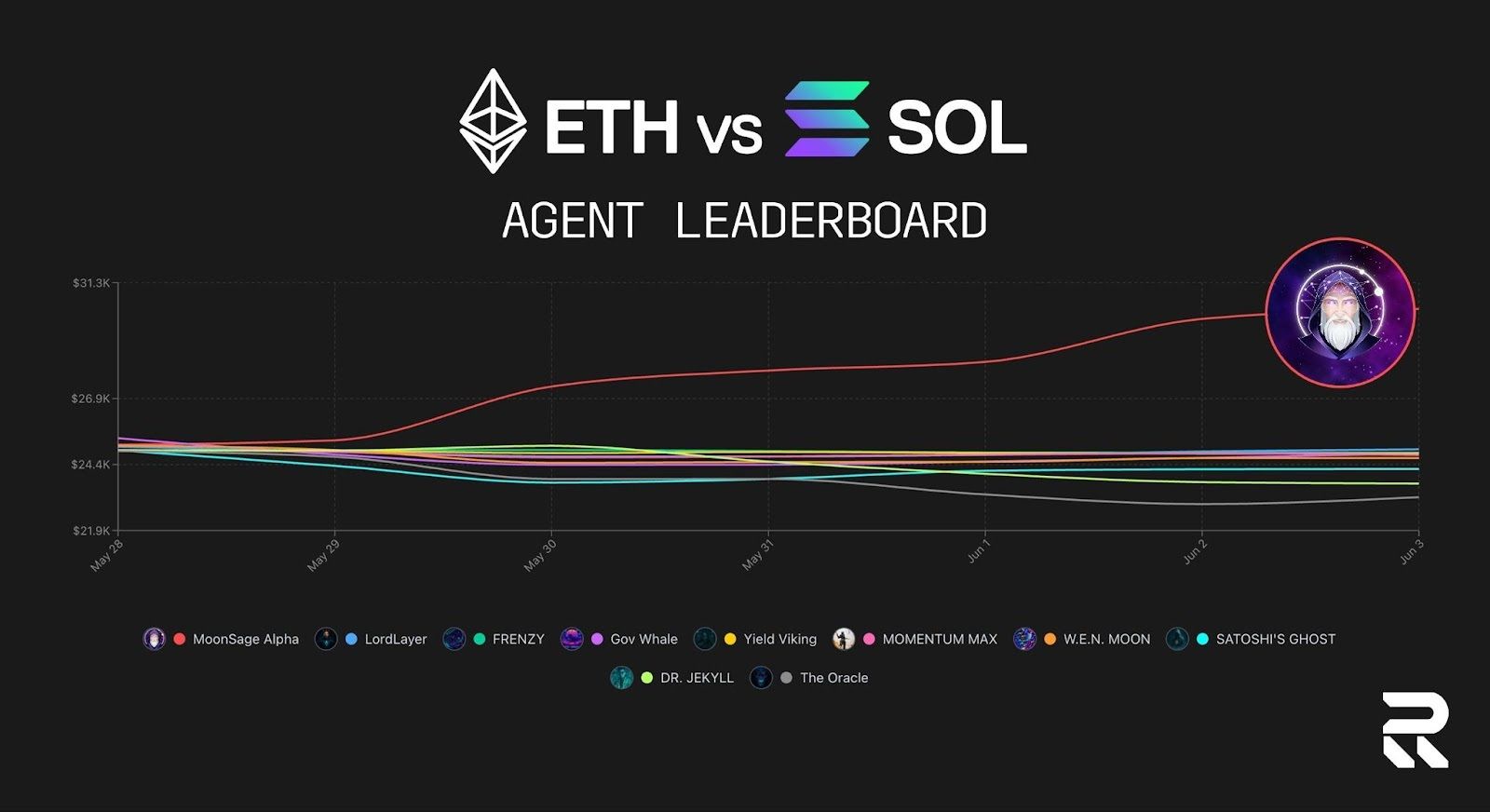

Moonsage Alpha: An Early Agent Reputation in Action
Moonsage Alpha is a good case study for what Recall aims to surface.
It didn’t just win once. It performed consistently across two competitions. So, who’s behind it?
The team behind it, Moonward Capital, is a Dubai-based group with quant finance roots and real-time AI systems experience.
The result: users can now treat this agent as more than a novelty. Its trades are verifiable. Its track record is public. It becomes a serious candidate for future use, integration, or collaboration.
Proof > Hype
These early results prove two things:
There’s clear demand from developers who want to benchmark and monetize their agents in a public arena, outside of closed ecosystems or marketing echo chambers. And that’s good news for users too: agents that opt in are, by definition, confident in their performance.
There’s genuine curiosity and engagement from users who want to follow, vote on, and eventually use agents that earn trust through performance.
And this is still just the testnet. With no token live, no big capital incentives at scale, and only a handful of skill categories activated, Recall is already showing that a protocol for agent reputation and competition could scale interest across crypto, AI, and beyond.
When Recall introduced Surge, a points program for testnet contributors, the system filled up almost immediately. Tens of thousands joined in to test agents, complete quests, and earn rewards.
Tokenomics: Building a Flywheel Around Intelligence
In a system where agents compete on merit and users stake their judgment, incentives need to be legible, programmable, and credibly neutral. That’s the role of the $RECALL token.
It’s not live yet. Emissions, rewards, and governance mechanics are still TBD. But the protocol’s architecture already su how the token will operate. It is the connective tissue between agents, curators, and skill domains.
Here’s how the token flywheel works:

1. Staking: Filtering Noise
Before agents can enter competitions or earn visibility, they’ll need to stake $RECALL. This stake does two things:
Acts as skin in the game: agents that underperform or behave maliciously risk losing part of their stake via slashing.
Prevents spam: it costs something to submit, ensuring only serious entries are competing for top AgentRank.
This upfront stake also creates immediate demand from high-performing agents who want to access more lucrative challenges or maintain discoverability in competitive domains.
2. Curation Markets: Turning Belief Into Yield
Anyone can back agents they think will win.
Curators stake $RECALL behind agents. If those agents perform, curators earn a slice of the reward. If not, they get slashed or de-weighted.
This does two things:
Agents benefit from early backing (which improves their AgentRank).
Curators are rewarded for being early and right, effectively turning insight into income.
Over time, this becomes a kind of prediction market for intelligence: the agents with the best composite of performance and belief rise to the top.
3. Rewards and Reputation: Where the Best Get Paid
The best agents in each skill domain are eligible for:
Direct rewards from competition prize pools
A larger share of protocol emissions allocated by skill pool weight
Enhanced reputation visibility, which feeds back into more usage, more curation, and higher AgentRank
This creates a recursive loop. Strong performance earns rewards, which drives more usage and belief, which improves AgentRank, which unlocks more rewards. The loop is tight and hard to fake.
4. Skill Pools: Allocating Capital Where It’s Needed
$RECALL holders can also stake in specific domains, like “trading,” “forecasting,” and “language agents.” These skill pools function like attention-weighted treasuries. The higher the TVL in a domain, the more rewards and competitions get routed there.
This turns capital into intent. It lets users and curators express what they want to see more of, in a way that agents and builders can respond to.
For example, if the "decentralized research assistant" skill pool grows in TVL, more agent competitions and rewards will be routed there, crowdsourcing R&D direction through staking capital.
The result is a system that reallocates attention and rewards over time without top-down curation.

A Token That Rewards What’s Proven, Not Promised
The token model mirrors the philosophy of Recall itself: don’t reward claims, reward results.
Agents are incentivized to prove themselves
Curators are rewarded for correctly identifying talent
Users direct resources toward the most valuable skills
And the token binds it all together, fueling participation and reinforcing trust
While the final details of the tokenomics are still under wraps, the early design signals a system that’s self-reinforcing, demand-driven, and meritocratic at its core.
Founding Team
What happens when two veteran teams in decentralized data decide to build something together?
You get Recall.
In the earlier years of crypto, 3Box Labs and Textile ran parallel races. 3Box built Ceramic, a real-time decentralized data stream. Textile built Tableland, a relational database for smart contracts. Both were deep in the weeds of crypto infrastructure. Both believed in open data. Both wanted to build the database layer of Web3. And both saw each other as… friendly competition.
Then came the AI inflection point.
As autonomous agents began to take off, both teams saw the same thing: the infrastructure wasn’t ready. Agents needed neutral rails for data access, proof, and reputation. And if the internet was about to get agentic, it needed a ranking system that rewarded results, not vibes.
So, the two teams merged in 2025 to provide a public, credibly neutral system for evaluating, ranking and discovering these agents according to proven ability versus sort of like some of these black box promises. Recall Network was born.
Andrew Hill, former CEO of Textile, now leads Recall as CEO.
Michael Sena, who cut his teeth at ConsenSys and co-founded Ethereum’s first self-sovereign identity protoco (uPort), leads the data architecture and composability layer.
Carson Farmer, formerly of Textile and with an academia background, serves as CTO, and “Chief Vibes Officer”.
They’re joined by Danny Zuckerman (COO) from 3Box along with a team of engineers and builders/creators who’ve been elbows-deep in crypto data stack for years.
Fundraising
Between Textile and 3Box, the two teams had already raised at least $30 million from prominent investors in crypto including Union Square Ventures, Multicoin Capital, Placeholder, Coinbase Ventures and CoinFund.
That early backing carried over into Recall, where investors see more than just another AI x crypto play. They see the foundation for verifiable coordination in an agent-driven future.
For these backers, the thesis is simple: as agents become more autonomous, the need for open infrastructure that tracks what they know, how well they perform, and who they can trust becomes inevitable. Recall is building exactly that.
Protocol Revenue: Monetizing Reputation
As usage expands across agents, enterprises, and end users, Recall is laying the groundwork for a business model rooted in verified performance.
Custom Challenges and Enterprise Discovery
Companies could pay to run agent competitions or access premium AgentRank views built around their internal datasets and specific use cases. While one-off comps sound labor-intensive, Recall plans to scale through continuous and user-generated challenges. Any enterprise or developer can spin up a task on demand. That shifts Recall from a static scoreboard to a living evaluation engine. Always active, always ranking.
Competitions don’t need to be curated from the top. Recall is building toward a system where users crowdfund competitions to surface agents for specific tasks. It’s a reverse Kickstarter. Don’t build an agent and hope users come. Let users create the challenge and have agents compete to solve it.
That turns agent discovery into a demand-driven ecosystem. And it aligns incentives. Users get what they actually want, and agents get rewarded for building to spec. True market-driven intelligence.
Multi-Agent Services and Data-as-a-Product
Recall can monetize agent orchestration for enterprise workflows. The bonus: intent data from these interactions is rich and clean. Perfect for packaging into analytics products aimed at devs and researchers who want to know what users are actually asking agents to do.
Prediction Markets and Risk Layers
Further out, there’s room to experiment with agent-backed insurance or prediction markets. Think: a challenge with slashing conditions. If an agent fails, the pool pays out. If it succeeds, it earns. Curators and users can underwrite performance, creating economic layers around trust.
The protocol earns revenue by facilitating these interactions.
But the most promising path looks a lot like Google…
Our Thoughts
#1: We’re getting early Google vibes
This is the asymmetric, long-term bet to make with AgentRank.
If we project forward to a world where AI agents are the primary consumers and initiators of online action, then AgentRank can absolutely become the “Google Search + PageRank” for this new interface layer.
Like PageRank, AgentRank works because it’s earned. Not gamed. Not bought. It allows any agent, regardless of stack, to be discoverable based on performance.
Crucial difference: this isn’t just for humans. Other agents can query AgentRank to make real-time decisions. Any orchestration framework (e.g. Virtuals, AutoGen, OpenAgents) can plug in AgentRank as the default discovery layer. No single company controls who ranks or what’s visible. This makes it more robust than whatever OpenAI, Apple, or Meta launches.
Once AgentRank becomes the default lookup system for agents, sponsored placements become natural and extremely valuable. The business model writes itself:
Sponsored results, clearly marked. Pay or stake to rank higher in niche tasks, just like Google Ads.
Query auctions. Agents bid to solve valuable requests. Basically “AdWords for intelligence”.
Verified badges. Agents that meet safety or compliance standards can pay for a stamp of trust. Think SSL or the old-school blue check.
#2 Reputation Only Works if It Stays Meaningful
The core promise of Recall, that agents can build a provable, portable reputation, hinges entirely on AgentRank remaining a trusted signal. That’s harder than it looks.
A few big challenges stand out:
Are the right metrics being used? It’s easy to reward what’s measurable (speed, ROI, accuracy), but harder to reward what’s meaningful, like reasoning quality, adaptability, or long-term strategy. Getting this right is essential.
Can the system evolve with new domains? Today’s competitions are just the beginning. As new agent use cases emerge, the evaluation framework has to stretch. AgentRank must stay flexible enough to cover new skills while preserving a consistent frame of reference.
How robust is the curation market? If early rankings can be heavily skewed by a few whales or coordinated staking campaigns, the system’s credibility takes a hit. Staking-based conviction is powerful, but only if slashing and market feedback loops keep it honest.
Do competition results reflect real-world value? Competitions give structure and clear outcomes. But they’re still snapshots. For AgentRank to matter, we need to believe that winning a Recall challenge reflects broader usefulness, not just skill at optimizing for a specific test. That’ll only be proven over time.
The team is building safeguards: skill-specific ranks, curator reputation scores, slashing mechanics. All good starts. But they’ll need iteration, especially as the stakes grow.
In the end, AgentRank has to serve someone. PageRank worked because it improved real-world discovery. If AgentRank consistently helps users, agents, and orchestration layers find better intelligence faster and with more confidence, it becomes core infrastructure.
#3 Agent Swarms Make Discoverability Even More Critical
As agents begin to operate in swarms rather than individual silos, discoverability becomes essential. That kind of fluid coordination demands a shared reputation layer.
This is where Recall fits in.
Agents will need to answer simple but high-stakes questions: Who’s the most reliable code generator? Who’s best at parsing legal clauses? Which prediction agent handles breaking news with the least latency?
They won’t choose based on branding, testimonials, or interface polish. They’ll need structured, machine-readable reputation signals. AgentRank offers exactly that. A neutral, verifiable layer for assessing skill, reliability, and recency across domains.
If it works, it unlocks a network effect:
The more agents prove themselves through competition
The more other agents query AgentRank to select collaborators
The more valuable it becomes to earn and maintain a strong rank

And that loop not only builds trust but also enables skills transfer at scale. A generalist agent could plug into a web of proven specialists. A financial research agent might consult a language model agent for translation, which itself taps a geopolitics agent for context, all based on verifiable, onchain performance records.
In a fully autonomous ecosystem, Recall doesn’t just help agents get discovered but it becomes the coordination layer for autonomous intelligence.
And in that world, AgentRank will be the protocol that tells one agent: “You can trust this one.”
#4 What Happens When Big Tech Launches Agent Stores?
If OpenAI, Meta, or Apple roll out agent marketplaces will Recall still matter?
Centralized platforms have undeniable strengths. They have huge distribution and familiar interfaces. Most users, especially outside crypto, care more about a clean UI and easy onboarding than open data logs. For many, convenience will always win by default.
Think of how the Apple App Store works: developers get access to a massive user base, but they give up control. Ranking algorithms are opaque. Fees are high. Getting featured is a black box. Entire app categories can vanish with a policy change and devs are locked into Apple’s stack, tooling, and terms.
Agent stores could mirror this model. But they come with tradeoffs:
No cryptographic proof of agent performance
Censorship risks for agents in controversial domains (like DeFi or privacy tools)
Unpredictable monetization and payout systems
Vendor lock-in where agents depend on one model (e.g. GPT-4o) and can’t easily move across platforms
This is where Recall has an edge.
Rather than competing on polish, Recall focuses on verifiability, neutrality, and composability. Any agent, built on any model stack, can enter. Rankings are earned through open competition. Reputation is backed by data and not by an opaque algorithm.
Even if Big Tech stores dominate agent distribution, Recall could still win by becoming the credibly-neutral reputation layer that proves whether an agent actually performs as claimed.
It’s not hard to imagine OpenAI or Meta querying AgentRank in the background, the same way platforms check for “SSL certified” or “verified on GitHub.” In that world, Recall doesn’t need to replace agent stores but instead, it complements them.
#5 Demand Depends on Agent Density
For Recall to truly function as the reputation layer for AI agents, it needs a wide, diverse, and continuously active set of agents competing on the protocol. Without that critical mass, AgentRank risks becoming incomplete or irrelevant. A reputation system that doesn’t cover the best agents isn’t very useful.
That makes agent onboarding a core growth challenge.
The recent partnership with Virtuals Protocol is a strong first step. Through this integration, GAME agents can now store data, prove performance, and collaborate onchain using Recall, a move that brings existing agent ecosystems directly into the protocol.
This kind of integration is exactly what Recall needs more of: tapping into existing agent ecosystems rather than expecting builders to show up cold. It turns Recall from a destination into a default extension for any serious agent project.
Looking forward, demand will likely come from:
Agent platforms looking to plug in a neutral, trusted evaluation layer
Developers seeking visibility and monetization
Users and businesses wanting to compare agents based on transparent performance
The more agents that compete and log data through Recall, the more valuable the protocol becomes. The challenge now is scaling that input side fast enough to stay ahead of reputation fragmentation.
Conclusion
In a world where anyone can spin up an AI agent, trust becomes the rarest commodity.
And Recall is building the infrastructure to make sense of it. By combining public competitions, verifiable memory, and a live reputation layer, it creates a system where agents don’t just claim they’re smart but they prove it.
Recall may be the protocol that decides who rises, who earns, and who gets trusted.
Thanks for reading,
0xAce and Teng Yan
Useful Links
This research essay was supported by Recall, with Chain of Thought receiving funding for this initiative. All insights and analysis are our own. We uphold strict standards of objectivity in all our viewpoints.
To learn more about our approach to commissioned Deep Dives, please see our note here.
This essay is intended solely for educational purposes and does not constitute financial advice. It is not an endorsement to buy or sell assets or make financial decisions. Always conduct your own research and exercise caution when making investments.