

You’ve probably never heard of Florence Lawrence.
In 1910, she became the first movie star to ever have her name appear on screen. Before her, actors were just “the girl” or “the man”, faceless performers in a studio system designed to keep them anonymous.

The First Movie Star, Florence Lawrence in 1910
The logic was simple: if the audience didn’t know their names, the actors couldn’t demand more money. Hollywood made millions, but its workers stayed invisible.
That slowly began to change. Names appeared in the credits. And royalties made sure that when a film was reused, whether on VHS, DVD, Netflix, or streaming syndication, the people who created it were remembered and paid.
That revolution has largely not happened for AI. Yet.
Every AI model you use is built on the work of people you never see. Doctors labeling cancer scans, researchers tagging fraud patterns, annotators scrubbing datasets, and millions of us writing the Reddit posts, Wikipedia entries, books, and GitHub repos that became training fuel.
The models built on their work scaled into billion-dollar products, while the people who made them possible vanished from the story.

The backlash started to spill into courtrooms. The New York Times sued OpenAI. Authors and developers launched class actions. GitHub Copilot was accused of regurgitating open-source code without attribution.
And yet, even as the lawsuits piled up, valuations soared: OpenAI is targeting a $1 trillion IPO, Anthropic raised billions, and Big Tech cemented control of the new AI studio system.
The invisible army of contributors has been left with nothing.
The Attribution Crisis in AI
The modern AI stack relies on three resources: data, models, and compute. Today, all three are controlled by a handful of tech giants. That centralization creates three critical distortions:
Value Extraction: Large AI companies capture nearly all the economic benefit while contributors get little to nothing.
Lack of Transparency: Creators rarely know how their work is being used, who’s profiting, or what downstream applications exist.
Misaligned Incentives: Without payments, there’s little motivation for contributors to share high-quality or specialized knowledge.
It is commonly estimated that between 60–90% of the data used to train large language models comes from individuals. Open-source developers, bloggers, researchers, artists. Almost none of the value flows back to them.
The result is what economists call a dual market failure:
On the supply side, contributors are underpaid and invisible.
On the demand side, businesses face expensive and opaque data markets.
It feels like Hollywood before royalties. Everyone can see the system is unfair, but it is the only one we have. Until someone rewrites the script.
A window of opportunity
There’s actually an interesting market opportunity in this sector right now. When Meta acquired 49% of Scale AI for $14 billion in June, it effectively set a price for the sector. Data training and labeling have become a multi-billion-dollar strategic moat.

Source: Forbes
With the acquisition, Scale just became less available. Meta’s gravity will pull it inward, leaving other AI labs scrambling for data partners. That creates a vacuum for new players.
Most buyers care about one thing: fast, affordable datasets. A smart and fast-moving company could capture a share of this market opportunity opening.
This is where the story of Codatta begins. Codatta is one of several companies trying to rebuild how data is aggregated and valued, using crypto as a coordination and verification layer. The question to ask is: Does Codatta have an edge?

Codatta promises data that’s not only more affordable but also verifiably higher trust than the incumbents. Its permissionless incentive design lowers data acquisition costs. Data purchasers can choose to train-first, pay-later, an option that traditional vendors don’t offer.
Codatta has a business model to serve both ends of the market:
Cash-rich enterprises (think Big Tech, regulated finance, healthcare) that want cost certainty.
Up-and-coming AI teams with high growth ceilings but limited budgets
Turning Data into an Asset Class
Most of us have been thinking about data all wrong.
We treat it like fuel. Burn it once to train a model, and the value is gone. But what if data worked like equity? Persistent and capable of compounding returns.
To make data behave like equity, you need four pieces in place:
Provenance: Each piece of data is tied to a wallet
Royalties: Contributors can earn recurring payouts whenever their data is used in training or inference
Quality at Scale: Ensuring that the system does not drown in noise
Privacy by Design: Raw data remains encrypted.
This is the bet Codatta is placing. They are building the plumbing for a new knowledge economy where data acts like an income-producing asset, and contributors get paid every time their work shows up in the model’s output.
Section I: Under the Hood
This section is a deep dive into how Codatta actually works. If you want to go straight into the business case, jump ahead to Section II

Codatta’s design starts with a deceptively simple distinction: separate X from Y.
X is raw input, like an image, a wallet trace, a scan.
Y is the human judgement that transforms it, such as labels, judgments, and annotations.
Most AI pipelines blur the line between the two. Annotation happens in the background, treated as labor in a black box. Codatta pulls Y into the foreground. Once human intelligence is visible, it can be attributed, scored, and paid.
That’s where Frontiers come in.
Frontiers: Modular Markets for Human Judgement
A Frontier is not a product. It’s not a dataset. It’s a programmable market for a specific kind of human input.
One Frontier might ask people to tag suspicious crypto wallets. Another might recruit optometrists to flag early-stage eye disease.
I like to think of each Frontier as a mini-app:
It has its own schema (what counts as a valid submission).
It has its own incentive design (fixed fee vs. royalties).
And it can run as long as demand exists, reusing data instead of discarding it.
Codatta grows by adding more of these focused, reusable Frontiers, each one a small engine for turning specialized judgment into an asset.
And none of it works without the hidden layer below.

A view of the available Frontiers on Codatta currently.
If Codatta is the storefront, the Codatta Protocol is the factory floor.
It stitches everything together behind the scenes. It handles cross-chain coordination, so attribution does not break as data moves. It runs validation logic so every raw input maps to a trustworthy judgment. It keeps payloads encrypted off-chain while anchoring proofs and metadata on-chain, giving you privacy and auditability at the same time.
And most importantly, it encodes incentives. That means royalties, penalties, staking mechanics. Everything flows through programmable contracts at the protocol level. Without this, it’d just be a fancier Mechanical Turk. With it, every contribution becomes a provenance-rich digital asset.
Submission to Asset
Every data asset starts as a single submission inside a Frontier. That’s where the pipeline begins.
The contributor uploads a file through a Frontier interface. The payload encrypts immediately on the client side. Codatta Protocol records the hash and metadata on-chain, while the encrypted content is routed off-chain to decentralized storage (IPFS, Greenfield) or a secure enclave. The system now knows the data exists, without ever seeing what’s inside.
Next, automated filters kick in. AI screens out spam, corrupted files, and duplicates. Each result is logged in Codatta’s lineage system, so future validators can trace exactly why something passed or failed.
Then the work shifts to people. The data is handed off to human reviewers, whose input carries different weights depending on their reputation. A high-score contributor in a medical Frontier, for example, might have triple the weight of a newcomer. These weights are baked into the protocol.
Once the human review settles into a decision, it moves to adjudication.
Validation in Codatta isn’t limited to judging labels. It applies to both sides of the pipeline:
Validating X (the sourced data): reviewing metadata such as device type, timestamp, camera details, or capture conditions to ensure authenticity and quality.
Validating Y (the label): evaluating whether the label is accurate, consistent, and aligned with task-specific rules.
Validators do more than click “approve” or “reject.” They can stake tokens behind their judgment, signaling confidence in the correctness of their decision. The protocol then resolves outcomes using reputation-weighted consensus:
If a validator’s call aligns with the final consensus, they earn fees
If they’re wrong, or worse, malicious, their staked tokens are slashed.
Validation becomes an economic commitment.
For enterprise-grade use, this step can run inside a Trusted Execution Environment. The data stays locked away, even from the processor itself. Codatta nodes verify that everything happened as claimed using attestation proofs.
Only then, after all filters, reviews, and proofs align, does the data become an asset. Codatta Protocol mints it with ownership and royalty logic embedded. It shows up in the marketplace, but it does not belong to Codatta. It belongs to the contributor and to every model that pays to use it.
When the Agents Show Up: ERC-8004 and x402
So far, this looks like a human-powered assembly line: people source data, reason about it, validate it, stake on it, and watch it turn into assets.
What I found most interesting about Codatta is how they’re already preparing for the moment when AI agents take on a larger share of that cognitive work. If agents are going to help build AI, they should be able to contribute, get credited, and get paid.
Codatta now supports this natively.
ERC-8004: A Real Seat for Agents
When a contribution enters the flow, AI agents can step in alongside human experts. Each agent is registered under ERC-8004, Ethereum’s emerging standard for agent identity and trust.
This gives every agent:
A persistent on-chain identity
A public reputation trail (accuracy, conflicts, slashing events)
Verifiable proof of what it contributed and when
A link back to data ownership and attribution
As agents do work, their output fits into the same sequence as humans:
Atomic contribution → data asset → dataset
ERC-8004 ensures the agent’s fingerprints stay attached to the resulting asset, so future royalties can flow correctly.
x402: Turning Usage Into Continuous Revenue
Once datasets are live, Codatta monetizes them the way AI actually consumes them: one request at a time. With x402, a client calling a paid endpoint receives a Payment request, completes the payment, and the request goes through.
Every call becomes a tiny royalty event, with revenue flowing instantly to the humans and agents whose work powered the result, and the remainder moving to the treasury.
Together, ERC-8004 and x402 turn Codatta into a hybrid ecosystem where humans supply expertise and agents supply scale, and both receive attribution and revenue.
Reputation: Portable Credit Histories for Knowledge
In a world of millions of micro-contributions, you need to know who to trust. That’s where reputation comes in.
Each participant in Codatta starts with a decentralized identity. Every action adds to your track record, a live credit file for knowledge work. The system watches four signals:
Accuracy & Agreement: Whether your past work consistently aligns with both ground truth and community consensus?
Behavioral Reliability: Do you deliver on time, respond promptly, and maintain high-quality, consistent work?
Staking‑as‑confidence: Do you stake behind your answers?
Recency: Staying active keeps your reputation warm.
As these signals stack, they shape what you can do. Higher reputation unlocks premium Frontiers, carries more weight in consensus, and earns a larger share of royalties. More influence, more upside.

And because it’s logged on the blockchain, reputation is portable. You do not start from zero when you join a new Frontier. Your identity brings a verifiable history that travels not just across Codatta but across any protocol plugged into the same layer.
This is the real promise of decentralized identity.
And it changes how people behave. It moves the mindset from short-term task completion to long-term equity building. You’re building a résumé that compounds and pays.
Hybrid Verification & The Arena
A permissionless system has one predictable failure mode. If anyone can contribute, most of what you get will be slop. You need a way to filter and course correct in real time.
Codatta’s solution has a two-tier loop:
AI first pass catches the obvious junk like duplicates, formatting errors
Human consensus adds the nuance AI can’t, with votes weighted by each contributor’s reputation and staked $XNY.
But the system goes further. Verification is layered.
Reputation & Staking: Contributors put skin in the game by staking $XNY.
Redundancy & Consensus: Tasks don’t rely on a single annotator. Multiple contributors work overlapping slices, and discrepancies are flagged for re-annotation until consensus emerges.
Continuous Monitoring: Datasets are monitored over time. If accuracy drifts, the system can auto-trigger new validation rounds
And then there’s Arena.
Arena is the test bench, kind of a public gauntlet for AI. It is where Codatta measures whether the data actually improves models. Counterintuitive as it sounds, most data does not.

How Codatta Arena Works
In Arena, two models answer the same prompt with their identities hidden. The crowd picks the better output. Every run, vote, and outcome is recorded publicly. Arena already compares more than thirty six frontier models, including GPT 4, Gemini, and Qwen.

Codatta Arena Leaderboard
But Arena isn’t limited to model vs. model. The same setup can test datasets. A model runs on its baseline training data. Then it runs again with fresh data from a Codatta Frontier added in. If performance improves on reasoning, accuracy, or consistency, the data gets real-world credit.
That’s the heart of it. Not just “is this label correct?” but “did this label make the model better?”
AI filters + Human validators + Staking incentives + Redundancy and continuous monitoring + Arena benchmarking → these form a feedback engine that keeps data accurate and useful.
Section II: The Business
In my earlier essay The Data Republic: Solving The Great AI Bottleneck, I wrote:
The ultimate vision is a living data economy. Networks that secure credible, high-fidelity data now will dictate training speed, model performance, and capture the largest share of future AI value.
So how does Codatta get there? At its core, Codatta is a marketplace that connects data buyers with the data contributors. Buyers access that data through an API.
Ongoing Attribution
Smart contracts on Codatta track which data units are pulled into training runs and which are accessed during inference calls. If a dataset is used, the contributors behind it earn. The logic sits on-chain and executes automatically.
Buyers choose how they want to pay for data access:
Fixed-Fee Payment: A clean, upfront license. You pay a set amount upfront, no surprises later. Ideal for big companies and regulated industries.
Train-Now, Pay-Later: Developers access data without upfront purchase. They train/build first, then royalties flow back to data owners when the model creates value.

But will contributors really accept “work now, maybe get paid later”? For most, probably not.
But this fits contributors who believe in the long-term value of a dataset or communities that want to share in the upside. Crucially, contributors choose with eyes open. They see the contract model before they opt in.
You can imagine that metering this can be a complicated challenge. And it is.
If the model runs inside the crypto ecosystem, powering on-chain agents or apps, usage can be made visible by design. Each paid call runs through a contract. The transaction records who called what, when, and at what price. That is enough to meter usage and route royalties automatically to the contributors behind the data.
But for Web2 enterprises, app revenue does not touch the chain by default. Here, datasets are licensed under clear contracts, closer to how SaaS or Bloomberg terminals work, with obligations, usage reporting, and the option for audits.
Even if end-app revenue remains opaque, royalties can still be linked to API-level metrics such as calls and tokens consumed. As long as those metrics are logged and attested, contributors get a transparent view of how their data is used.
In short:
On-chain apps → automatic settlement.
Off-chain apps → licensing + API usage reporting
Same as Spotify? Nah.
The royalty model used in Codatta reminds me a lot of music licensing. When a song plays, the artist receives a royalty. When a validated dataset gets used, the contributor earns. The difference is that in Codatta, the relationship between usage and value is traceable and programmable.
This changes how contributors think. Instead of labeling for a flat payout, you are building a portfolio of high-leverage data points. Reputation and earnings grow with reuse.
There is a familiar worry here. In music, only a tiny share of artists make real money. Spotify’s own payout model breaks down to roughly $0.003 per stream, meaning one million plays translates to about $3,000. This means the long tail of artists (99%) will not be able to make a meaningful living solely from royalties.
Codatta avoids that trap by tying royalties to performance, not volume. In AI, a small, rare dataset can measurably shift a model. A handful of labeled tumors, a novel wallet exploit, a linguistic quirk, any of these can change downstream results.
The protocol tracks what gets reused and what improves outcomes. Contributors who surface high signal data earn more, not because they uploaded more, but because their contribution moved the needle.
The goal is not to make every annotator wealthy. It is to make sure that when your data matters, the rewards keep coming.
Proof in Action: Codatta’s Early Datasets
Codatta has begun to show that it can aggregate large, high signal datasets, not just talk about them.
Take MM-Food-100K, a dataset that looks quite simple: 100,000 images of food, annotated with ingredients, portions, nutrition, and context. What’s different is the way it was built.
Instead of paying annotators pennies upfront, Codatta launched the Booster campaign in partnership with Binance Wallet. Thousands of Binance users were funneled into contribution tasks, incentivized with $XNY, and plugged into Codatta’s full infrastructure stack at scale.
In just six weeks, 87,000 contributors uploaded 1.2 million validated samples with real photos, real annotations, each one tied to a wallet address for verifiable provenance.

Source: MM-Food-100k Dataset
The release strategy was deliberate:
10% of the dataset was released freely for public research (already downloaded over 1,000 times on HuggingFace in the past month).
90% was retained for commercial licensing, with royalties flowing back to contributors whenever that data trains a model or powers an app.
Models fine-tuned on MM-Food-100K consistently outperformed baselines in calorie estimation and food classification. In other words, the dataset made AI smarter.
Codatta is now running the same playbook on Binance Wallet data, crypto account annotation, and robotics.
In the crypto use case, contributors label wallet addresses with structured metadata: “exchange,” “whale,” “OTC desk,” “scam cluster.” This kind of annotation turns raw transaction logs into usable intelligence for compliance and risk analysis.

A few live contribution tasks for Crypto Account annotations
Traditionally, this work has been locked inside proprietary firms like Chainalysis or Arkham, where maintaining a labeled address database can cost $10–30 per address. Codatta does it differently and is likely cheaper. It opens the process to the crowd but still maintains quality through protocol-level enforcement: reputation scoring, staking penalties, task redundancy, and consensus checks.
The robotics use case makes the idea concrete. Contributors tag video clips of robot behavior, describing each action frame by frame. I tried it. The interface was simple, the instructions clear, and the rewards posted instantly. It is tedious work, which is exactly why incentives matter.

Annotating robotic actions in the displayed video
These datasets are still early. The real test will come when developers use them to train perception and planning models, and we see whether performance moves.
Strategy Behind the Pilots
These early Frontiers are not about chasing revenue. They are proof points. Codatta is showing that its system can support real contributors, manage complex labeling, and produce data that improves model performance.
Each pilot serves two purposes. First, it validates that Codatta’s infrastructure can generate high-quality data across very different sectors. Second, it gives enterprise buyers a live example of what it looks like to launch a Frontier and get usable output.
Codatta is not waiting for custom enterprise requests, which may take time due to the long sales cycle. It is putting results in the field to build proof and pull demand. These early datasets are the bait.
Who is The Buyer?
Codatta’s sweet spot will be in sectors where annotated data is essential but the existing pipeline is overpriced or missing entirely.
In healthcare and DeSci, independent labs and DAOs can fund studies but lack structured, compliant data. Codatta fills that gap. Contributors upload annotated scans, lab notes, and trial results. Researchers get auditable datasets without begging pharma or academia for access.
Data for robotics is expensive because it’s hard to capture. Companies like Figure AI now partner with real estate giants to film humans inside 100,000+ homes. Codatta offers another route: global contributors can supply labeled sequences at scale, more cheaply.
In DeFi, on-chain flows are public, but intelligence is not. Firms spend heavily on proprietary wallet labels. With Codatta, contributors surface patterns, flag fraud, and tag address types, earning a stake in every product that uses their work. Buyers get a continuous stream of structured intelligence.
The throughline is simple. Synthetic data cannot beat real, high-signal human input.
One of the first real-world tests came through its partnership with KiteAI, a Layer-1 network focused on autonomous agents. We covered Kite recently, and it was through that team that I first met Yi (founder) and Codatta up close.
The collaboration gave Codatta access to a growing ecosystem of agent teams. But more importantly, it unlocked real-world data, starting with healthcare.
One Frontier focused on blood film images used in cancer diagnosis. Doctors and medical students annotated thousands of slides, tagging anomalies that could signal leukemia. Blurry cell clusters became structured inputs. Those models now run directly on the Kite network, learning from domain-specific, human-labeled examples instead of generic corpora.
We heard the data proved so useful that some institutions tried to buy exclusive rights to it.

Codatta also partnered with Alibaba Cloud, connecting its contributor network with Alibaba’s Qwen family of models and the PAI platform.
This matters because Alibaba Cloud already serves 150,000+ global customers, including 90,000 enterprises using Qwen models. Plugging community-driven datasets into that environment expands the demand pool. Developers and enterprises can tap domain-specific data without leaving Alibaba’s ecosystem. For Codatta, it opens a distribution channel into one of the largest AI developer bases in the world.

Beyond that, the team shared with me that early-stage AI startups in healthcare and robotics have already reached out for structured, high-quality data pipelines rather than raw data dumps. And a major enterprise AI lab (still unnamed) is preparing to launch its own Frontier once the royalty and privacy mechanics are finalized.
Today’s datasets are just the warmup. The next phase will bring enterprise-grade campaigns.
From Alipay to Attribution: Why This Team Built Codatta
Codatta began with a frustration that kept following its founder.
Yi Zhang, now CEO, spent years deep inside Web2 data infrastructure. At Ant Group as an engineering manager, he ran analytics for Alipay’s merchant apps, which handled billions of impressions daily. He could trace user behavior across touchpoints, segment patterns, catch fraud, but the underlying data came from black boxes. No way to verify without begging for access.

Codatta’s CEO, Yi Zhang, on a podcast with the Kite AI team.
That tension followed him. In his PhD work, Yi had studied recommendation systems, algorithms that rank what we see. He learned that relevance is fragile. Clicks, feedback loops, outliers, spam all bend the signal. Without traceability, even the best models overfit to noise.
He saw the same pattern everywhere: AI systems need clean, verifiable data, and Web2 was never built to deliver it.
By 2022, as Web3 and AI started to converge, he pulled two colleagues into the problem. Paul Pang (CTO), who had built backend platforms under heavy load, and Kevin Wang (CPO), who had shaped analytics features where interface design mattered as much as math. The three sketched a protocol where contributors supply structured metadata, validators cross-check it, and smart contracts reward or penalize based on quality.
Their insight was simple. You cannot treat data as bulk commodities. You need data that’s ownable, verifiable, and modular. That means annotations must carry cryptographic proofs, staking, reputation, and rejection mechanisms. The architecture becomes economic as much as technical.
That blueprint became Codatta.
They incorporated in 2023 and launched a beta in April 2024, seeded with over 500 million pre-labeled addresses. The team has raised $4 million so far from OKX Ventures, with participation from Comma3, Mask Network, Paramita, Web3Port, and several strategic angels from Coinbase and Pinterest.

Because they knew chasing scale without quality is a trap, they baked hybrid validation (AI + human + staking) into the core. They also designed contributor incentives and royalties so that annotation isn’t a one-off bounty but a long-tail revenue stream.
Yi talks about building “trusted, perpetual data rails,” where accuracy is what earns.
So…Codatta is what happens when engineers who built inside opaque systems try to rebuild the whole thing from first principles. It’s fascinating to see.
Section III: Tokenomics
Codatta has a live token, XNY, with a market cap of $9M and a fully diluted valuation of $36M (as of 1 December 2025).
In a decentralized protocol, the token is the coordination layer. Without it, there’s no way to coordinate contributors, validators, and consumers at scale. XNY is the accounting unit.
Supply Mechanics
Total Supply: 10B
Circulating Supply: 2.5B (25%)
Key Allocations: ~50% to team (18%), investors (12.5%), and the foundation (21.5%); ~48% to community incentives (airdrops, bounties)
TGE: 23rd July, 2025
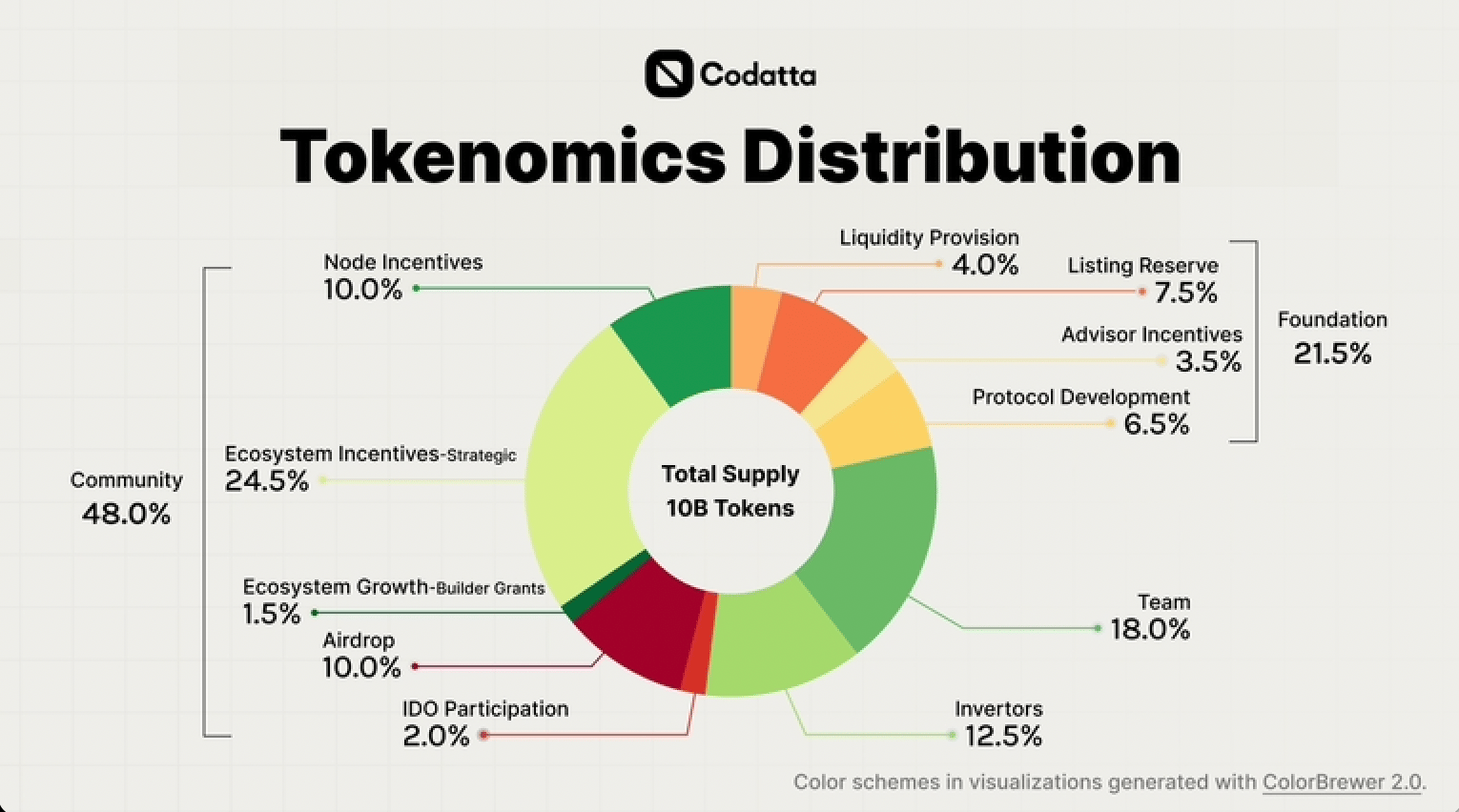

Roughly half of the total supply sits with the team, investors, and the foundation, and most of those allocations stay locked until July 2026. That cliff defines next year’s risk. If demand has not scaled by then, the market could struggle to absorb insider unlocks.
On the community side, distribution is gradual. The airdrop has been completed, but emissions from validator rewards and contributor payouts will expand supply over time. This gives the ecosystem a roughly 12-month window to build genuine demand before inflation accelerates.
Codatta’s social footprint is unusually large for its age: ~233 K Twitter followers, 69 K Telegram members, and 15K Discord users. That visibility helped drive early liquidity. The real test is whether the on-chain activity can keep pace.

XNY starts with a modest float and a compressed valuation base. Over the next year, it needs to prove that staking, licensing, and enterprise usage can scale fast enough to meet the 2026 unlock wave.
Demand Mechanics
XNY has no meme premium. Its value depends entirely on whether Codatta becomes an active marketplace. Each demand vector ties to real usage.
Where XNY Gets Used
1. Contribution and Verification Fees
Each annotation or validation on the network costs XNY. The more complex the task, the more it burns. This creates a baseline token sink tied to network throughput. Today, those flows remain small because most usage is bootstrapped through incentives
2. Data Licensing
If an enterprise wants access to Codatta’s proprietary datasets or API firehose, they’ll need to pay. Eventually, in XNY. For now, it’s mostly fiat or stablecoins, but smart contracts are coming. The plan: auto-convert a chunk of every licensing fee into XNY.
3. Task Launch and Promotion
Enterprises that want to independently launch tasks on Codatta must deposit XNY. This applies to opening bounties, setting SLAs, and reserving contributor capacity. Task promotion (faster matching, higher visibility) requires XNY as well.
4. Staking and Slashing
Validators stake XNY to signal credibility. Higher stakes earn validation fees, priority assignment, and dispute rewards. Low-quality or malicious work gets slashed. Contributors can stake as well, functioning as a reputation amplifier. It unlocks higher-quality tasks, adds weight in consensus, and increases their share of rewards and royalties.
5. Governance
Holders vote on reward rates, dataset standards, and treasury allocation. This is not daily demand, but it ties token ownership to network direction.
6. Ownership Liquidity (Future)
Codatta is exploring ways to make data assets tradable, from fractional ownership to bundled portfolios. XNY would handle settlement and listing. This remains early but fits the broader aim of treating data as an investable asset.
Revenue & Flow-Through to Token
To me, the core question for any work token is simple. Can real revenue cycle back into real token demand? Codatta’s design creates three overlapping streams that, over time, could give XNY an actual economic floor.
1. Managed-Service Revenue (Today’s Activity)
This is the business that exists today. Codatta already earns revenue in fiat and USDC from clients using its labeling service. These are not huge deals, but they matter because they show buyers will pay for structured, verified data.
CipherOwl: recurring monthly spend in the low-five-figure range.
RoboFlex: 16-month contract worth roughly $250K.
DepathAI and other medical clients: pay-per-volume data processing.
Around 70–80 % of revenue flows directly to annotators and infrastructure providers, while 20–30 % remains as gross margin. In the near term, this margin sustains operations and, if the team sticks to its policy, will be partially converted to XNY for treasury reserves and staking pools.
This portion of the business behaves like SaaS: predictable, contract-based, and denominated in stablecoins. It does not yet require XNY, but it establishes a revenue baseline that can later migrate on-chain.
2. Royalty-Bearing Data Licenses (Medium-Term Growth Engine)
This is the growth engine. In Codatta’s system, every atomic contribution becomes a data asset, and assets aggregate into datasets. Both are on-chain primitives with programmable ownership and royalty rights.
Enterprises pay for access in XNY or in fiat automatically converted via smart-contract swap.
Contributors receive recurring royalties (60–70 % of license fees).
Treasury captures the remaining share as protocol revenue.
Let’s do some back-of-napkin math. If Codatta signs a few dozen licensing contracts averaging $200,000/year (not expensive for data buyers), it moves into eight-figure ARR territory.
Because licensing flows through contracts, part of every payment must buy XNY. This is where revenue becomes token demand.
3. Marketplace & Gas Fees (Always-On Sink)
Every upload, annotation, or dataset transfer incurs a 1–2 % transaction fee in XNY, part burned and part redistributed to node operators. At low volume, this is noise. At scale, it becomes an always-on sink that counterweights emissions.
Putting It Together
The value chain flows as follows:
Enterprises pay fiat or XNY for data services.
Smart contracts split revenue among contributors, validators, backers, and the treasury.
Treasury periodically uses surplus to stake, buy back, or burn tokens.
Participants restake earnings to improve reputation, locking supply.
If managed well, this forms a feedback loop where higher activity increases both token velocity and locked value without uncontrolled inflation.

Over the next 6 to 18 months, XNY should be treated as a high-risk, high-upside bet on whether Codatta can turn early traction into real usage. That means millions of labeled datapoints, active staking, and enterprise licensing revenue. If those pillars materialize, XNY becomes more than a work token. It becomes a coordination layer for knowledge across AI networks.
Execution risk is real, especially around product delivery and unlock timing.
Key metrics to monitor:
Usage Growth: Number of contributors, datasets submitted, and annotation throughput.
Revenue/Burn Flow: Ratio of fees burned versus tokens emitted for rewards.
Liquidity: Depth and exchange diversity; watch for Tier-1 listings.
Community Sentiment: Consistency of engagement across Discord and X; monitor for inorganic spikes.
Technical Progress: Marketplace rollout, governance activation, and staking performance.
Some Parting Thoughts
#1: The Decentralized Data Race
Codatta is not alone in trying to rewrite data economics. Vana and OpenLedger are the two other serious experiments.
Vana is focused on personal data collectives (Data DAOs). Individuals contribute browsing history, health logs, music playlists, and pool them into tokenized Data DAOs. The appeal is privacy and control. It lowers the bar for participation.
OpenLedger (we also wrote on them previously) is closer to Codatta’s territory. It wants everything recorded end-to-end. Data, models, and agents are all on chain with attribution tracked from input to output, and payments are routed through Proof of Attribution. It is dense, integrated, and ambitious.
Codatta takes a narrower path. It focuses on structured annotation and reusable knowledge. It does not require teams to switch platforms or adopt new models. It slots into existing workflows. Buyers can license datasets, track usage, and issue royalties without changing infrastructure.
Where Codatta gets especially interesting is in how it treats every dataset as a digital asset. I can imagine an entirely new set of markets forming around it. Just as music royalties can be traded and fractionally owned, so too could datasets.
Funds might assemble portfolios across robotics, healthcare, and finance. Data-backed lending or yield-bearing datasets could emerge. Codatta wants to build the royalty layer for structured knowledge.
#2: Personal AI Will Need Personal Data
Personal AI is coming fast. Agents and copilots are already learning preferences and behavioral patterns. But to actually work, they’ll need to be trained on deeply personal data: health logs, shopping habits, conversations, even voice recordings.
Today, Big Tech collects that data quietly, without user control or compensation.
Codatta unlocks a different path: opt-in, contribution of personal data where royalties flow if that data powers useful models. Not everyone will participate. But many will, especially when trust and payment are built in
Imagine:
Fitness data shared into a health AI, with contributors earning whenever that dataset is licensed.
Browsing or shopping behaviors pooled into preference datasets for recommendation models.
Voice and text logs contributing to better personal assistants
In other words, if personal AI is the next platform shift, personal data is the scarce input. Codatta can provide the rails that make it accessible and rewarding for the people who contribute to it.
Conclusion
Every blockbuster movie needs its credits. For too long, AI has been running on invisible labour of annotators, experts, and communities, whose names never scroll and whose checks never arrive.
By turning data into assets, royalties into rails, and contributors into stakeholders, Codatta is building the Knowledge Layer that AI has been missing.
The bet is simple: if compute was the scarce commodity of the last cycle, knowledge is the scarce commodity of this one. And if I use that lens, Codatta stops looking like a plain vanilla data marketplace, and starts looking like the infrastructure that makes sure the people who build the future get paid for it.
Roll credits.
Thanks for reading,
0xAce and Teng Yan
Useful Links:
If you enjoyed this, you’ll probably like the rest of what we do:
Chainofthought.xyz: Weekly AI/Robotics x Crypto newsletter & deep dives
Agents.chainofthought.xyz: Weekly AI Agent newsletter & deep dives (non-crypto)
Our Decentralized AI canon 2025: our open library and industry reports
Prefer watching? Tune in on YouTube. You can also find me on X. Follow 0xAce too.
This essay was supported by Codatta, with Chain of Thought receiving funding for this initiative. All insights and analyses are our own. We uphold strict standards of objectivity in all our viewpoints.
This essay is intended solely for educational purposes and does not constitute financial advice. It is not an endorsement to buy or sell assets or make financial decisions. Always conduct your own research and exercise caution when making investments.